Hardwood is a minimal-dependency Java library for reading Parquet files. It currently has row-reader and columnar-reader APIs, with Parquet writing planned for the future.
Gunnar Morling, Hardwood’s author, published some initial benchmarks in the v1.0 announcement, comparing Hardwood’s row and column readers against Parquet Java. Those benchmarks measured read speed against already-downloaded Parquet files.
Gunnar’s benchmarks ran on an m7i.2xlarge, with 8 vCPUs / 4 physical cores. Each test used three variants:
Hardwood with decoder threads =
Runtime.getRuntime().availableProcessors(), which equals 8Hardwood pinned to one CPU thread with taskset
Parquet Java, single-threaded
I was curious how the same benchmarks would look on my Threadripper 9980X: 64 cores / 128 threads, with 256 GB ECC DDR5. I modified Gunnar’s benchmark code to also test Hardwood with fixed decoder-thread counts: 1, 4, and 8.
That gives the following Threadripper variants:
Hardwood, unpinned, decoder threads = 128 (available processors)
Hardwood, unpinned, decoder threads = 8
Hardwood, unpinned, decoder threads = 4
Hardwood, unpinned, decoder threads = 1
Hardwood pinned to one CPU thread (taskset)
Parquet Java, single-threaded
One important detail: decoder threads = 1 is not the same as the pinned 1-core test. With decoder threads = 1, the main thread can run on another core. The pinned test constrains the whole process to one logical CPU which is the closest we can get for like-for-like comparison to single-threaded Parquet Java.
Flat full scan (columnar reader)
This benchmark reads all columns of the dataset 48M row dataset.
m7i.2xlarge
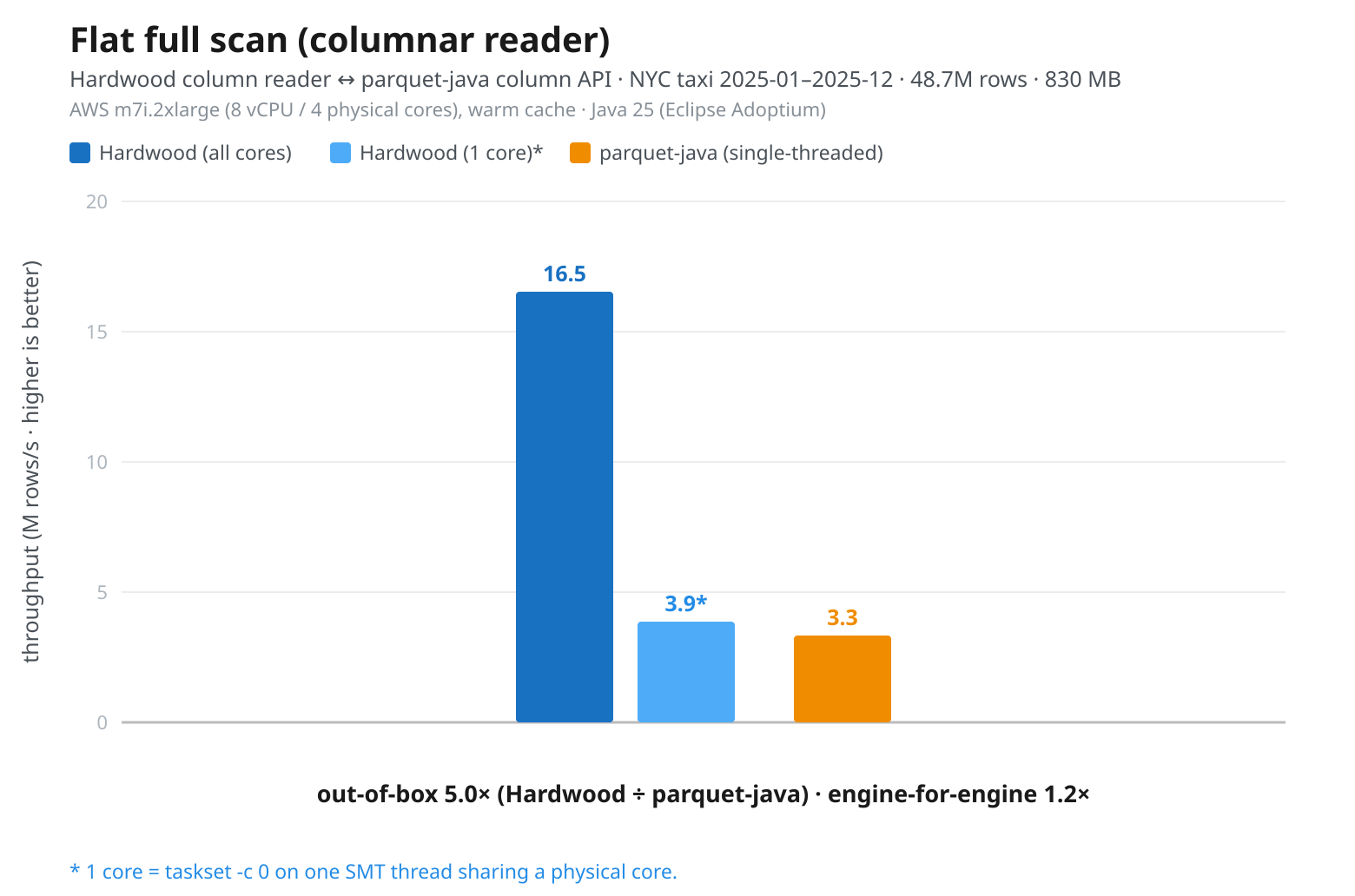
Fig 1: m7i.2xlarge, Hardwood (all cores) 16.5M/s, Hardwood pinned 1-core 3.9M/s, Parquet Java (single-threaded) 3.3M/s
Threadripper 9980X
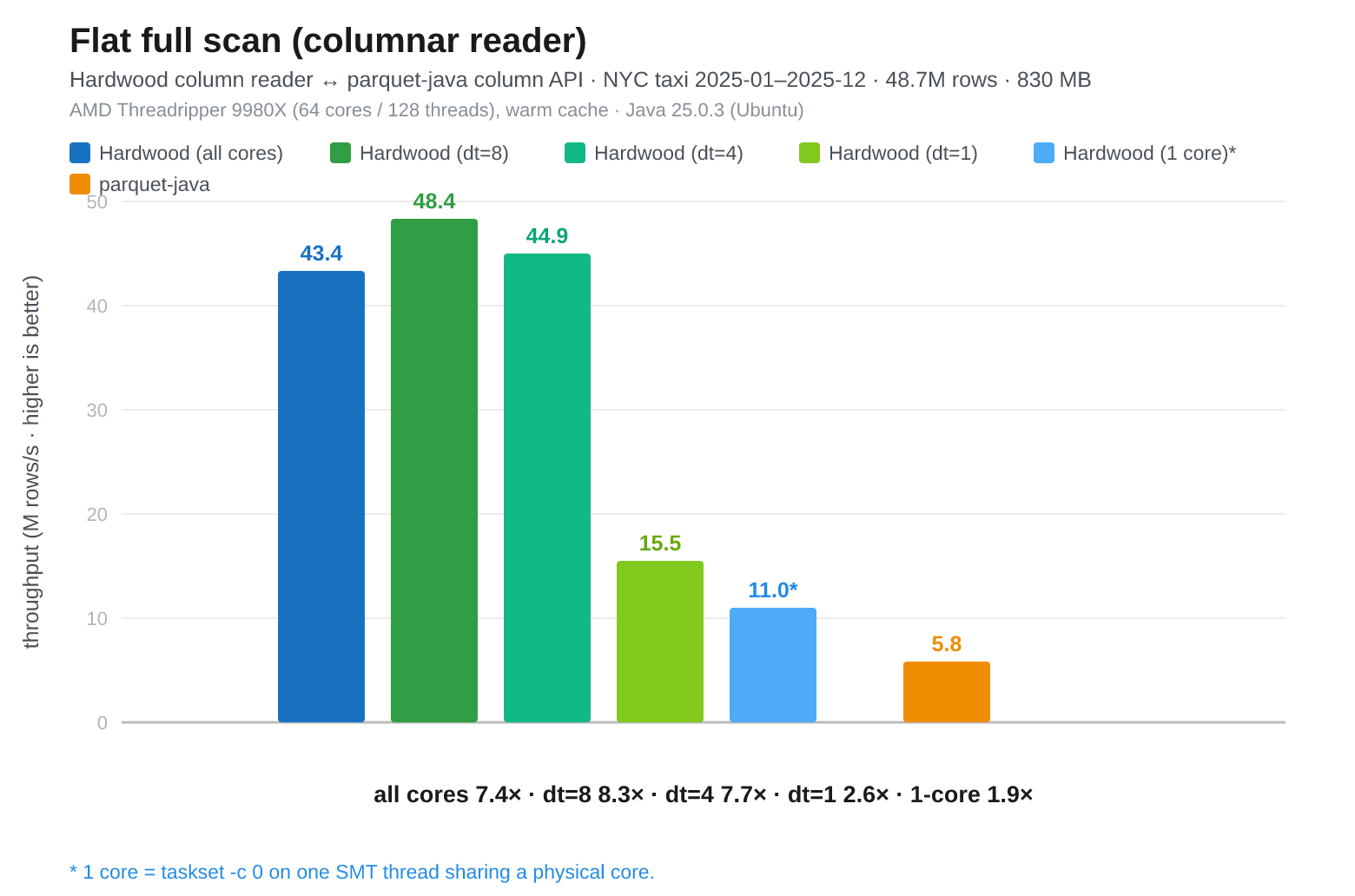
Fig 2: Threadripper, Hardwood (all cores) 43.4M/s, Hardwood dt=8 48.4M/s, Hardwood dt=4 44.9M/s, Hardwood dt=1 15.5.9M/s, Hardwood pinned 1-core 11.0M/s, Parquet Java (single-threaded) 5.8M/s
A few things stand out:
The Threadripper is much faster in the single-core cases than the m7i.2xlarge. Hardwood pinned to one core reaches 11.0M rows/s (with some runs reaching over 12M), versus 3.9M rows/s on the m7i.2xlarge. Generally about 3x faster.
Hardwood’s single-core result on the Threadripper is also much stronger relative to Parquet Java. On the m7i.2xlarge, Hardwood 1-core is only modestly ahead of Parquet Java: 3.9M rows/s versus 3.3M rows/s. On the Threadripper, Hardwood 1-core is almost 2x faster: 11.0M rows/s versus 5.8M rows/s.
More decoder threads help, but only up to a point. The best result here is 8 decoder threads, at 48.4M rows/s. Four decoder threads are close behind at 44.9M rows/s. The default availableProcessors() setting, which gives 128 decoder threads on this machine, is slower than both, which is not surprising.
Flat full scan (row reader)
This benchmark reads all rows of the dataset 48M row dataset. It has two variants:
Indexed (positional) columns, i.e. r.getLong(3)
Named-columns, i.e. r.getLong("passenger_count")
m7i.2xlarge
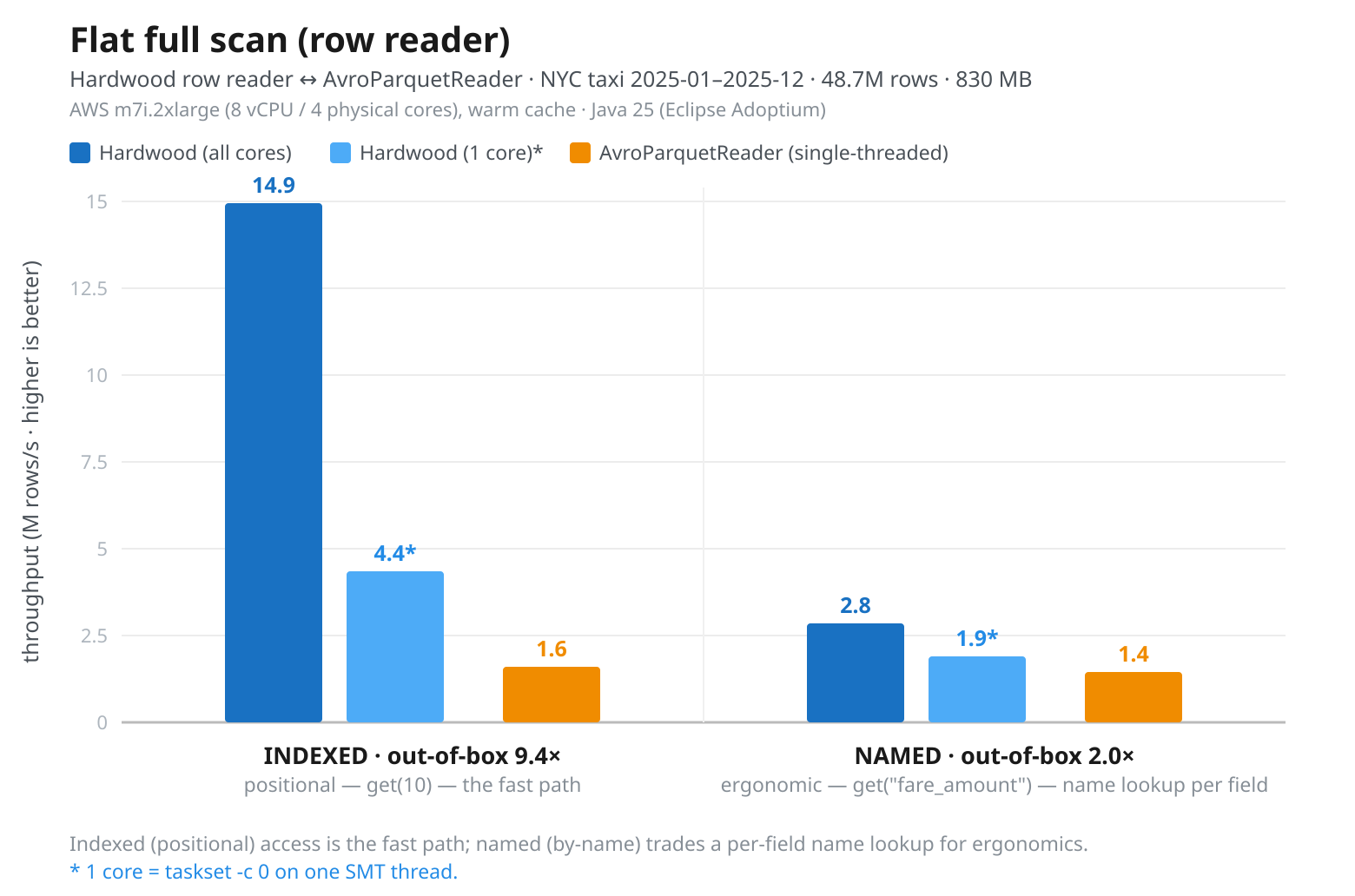
Fig 3: m7i.2xlarge, Indexed-columns, Hardwood (all cores) 14.9M/s, Hardwood 1-core 4.4M/s, Parquet Java (single-threaded) 1.4M/s. Named-columns, Hardwood (all cores) 2.8M/s, Hardwood 1-core 1.9M/s, Parquet Java (single-threaded) 1.4M/s
Threadripper 9980X
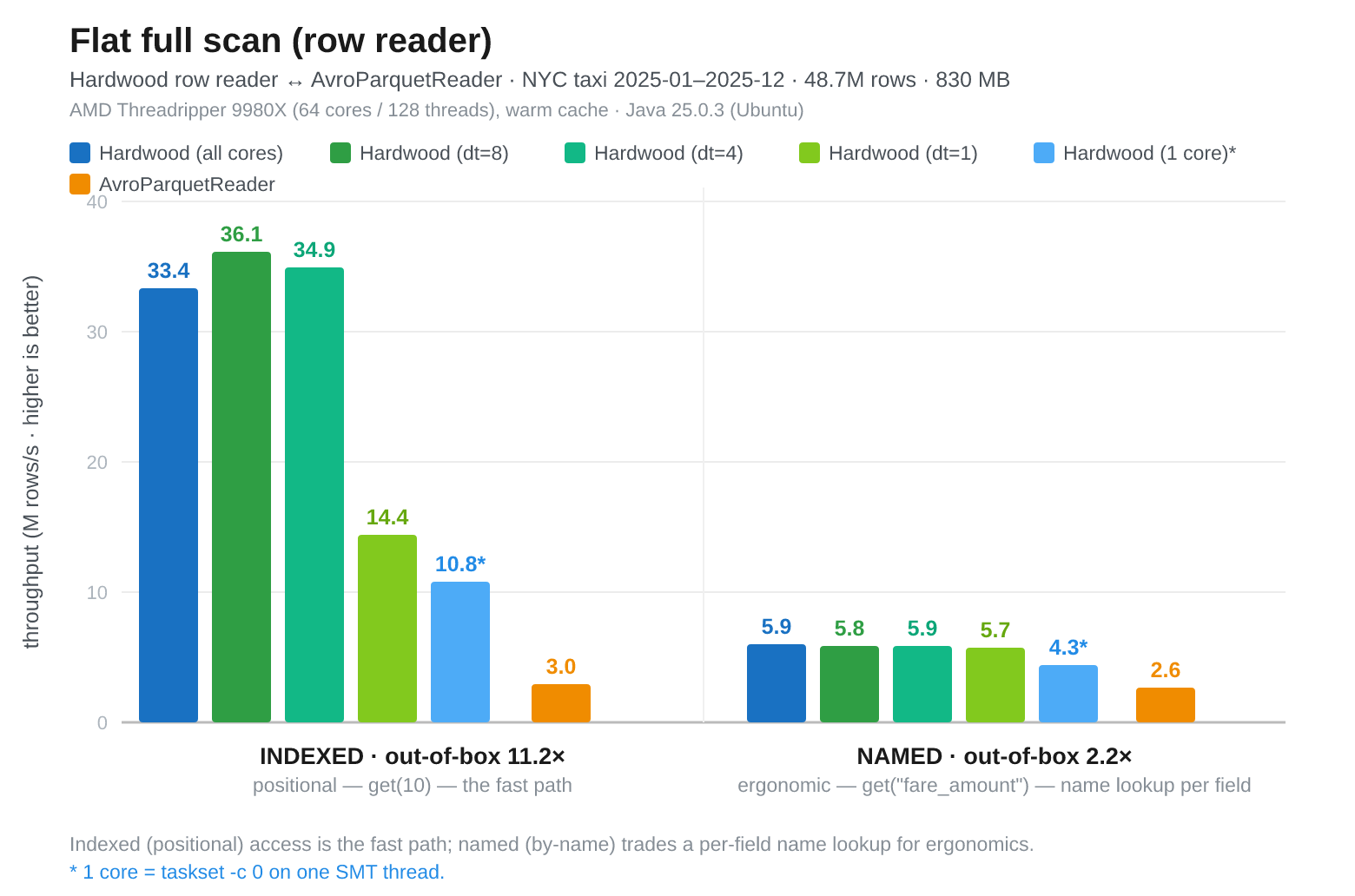
Fig 4: Threadripper, indexed (positional) columns, Hardwood (all cores) 33.4M/s, Hardwood dt=8 36.1M/s, Hardwood dt=4 34.9M/s, Hardwood dt=1 14.4M/s, Hardwood pinned 1-core 10.8M/s, Parquet Java (single-threaded) 3M/s. Named columns, Hardwood (all cores) 5.9M/s, Hardwood dt=8 5.8M/s, Hardwood dt=4 5.9M/s, Hardwood dt=1 5.7M/s, Hardwood pinned 1-core 4.3M/s, Parquet Java (single-threaded) 2.6M/s
The indexed-column row reader shows the same basic pattern as the columnar full scan. Hardwood is much faster than Parquet Java even in the pinned 1-core case: 10.8M rows/s versus 3.0M rows/s. The best multi-threaded result is again with 8 decoder threads, at 36.1M rows/s, with 4 decoder threads close behind.
The named-column reader is different. Hardwood is still ahead of Parquet Java, but it does not meaningfully scale with decoder threads. The unpinned Hardwood results are all around 5.7M to 5.9M rows/s, regardless of whether the benchmark uses 1, 4, 8, or 128 decoder threads.
If you want high throughput, use the indexed-column approach.
Flat filtered scan (column reader)
This test generates data with 4 columns and 50M rows where event_time is perfectly ordered. The filter is event_time < threshold, and therefore the file is therefore clustered by the predicate column, relying on Parquet row-group/page/column statistics. The file contains no bloom filters as Hardwood does not support those yet). There are two variants:
selective: event_time < 2,500,000 (about 5% pass)
matchAll: event_time < 50,000,000 (100% pass)
The test measures the time for the filtered scan to complete.
m7i.2xlarge
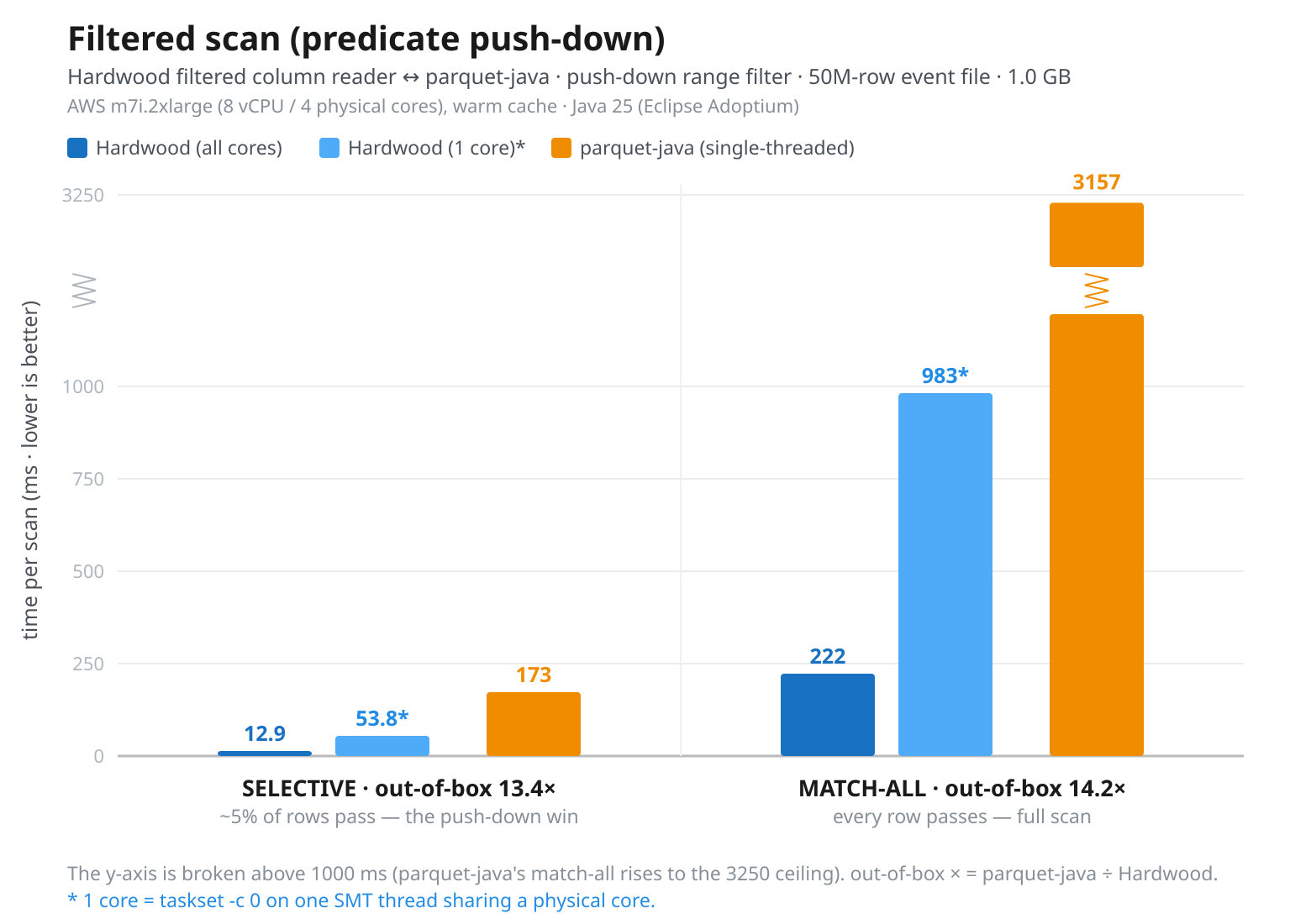
Fig 5: Selective (5%), Hardwood (all cores) 12.9 ms, Hardwood pinned 1-core 53.8 ms, Parquet Java (single-threaded) 173 ms. Match-all (100%), Hardwood (all cores) 222 ms, Hardwood pinned 1-core 983 ms, Parquet Java (single-threaded) 3157 ms
Threadripper
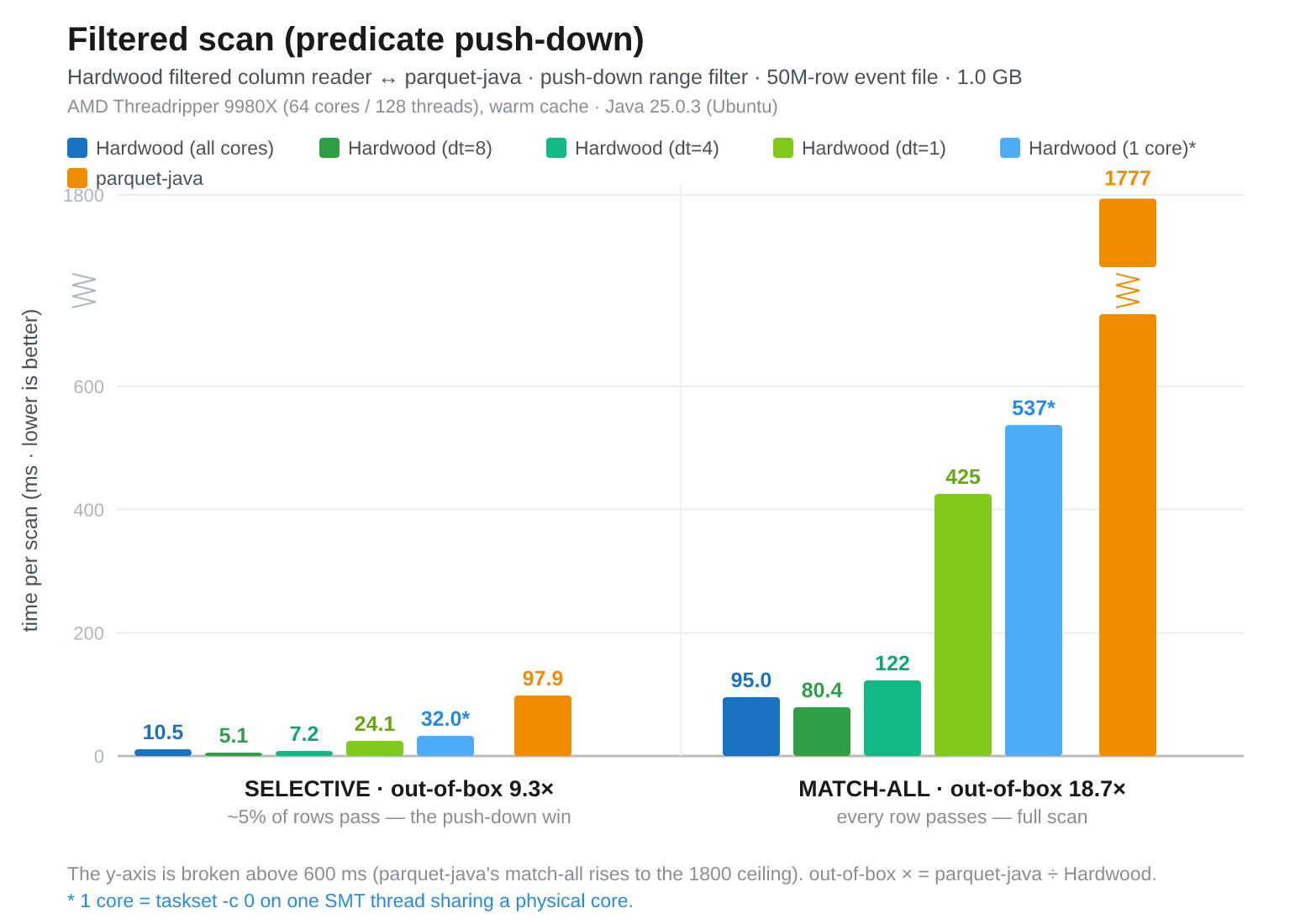
Fig 6: Selective (5%), Hardwood (all cores) 10.5 ms, Hardwood dt=8 5.1 ms, Hardwood dt=4 7.2 ms, Hardwood dt=1 24.1 ms, Hardwood pinned 1-core 32.0 ms, Parquet Java (single-threaded) 97.9 ms. Match-all (100%), Hardwood (all cores) 95.0 ms, Hardwood dt=8 80.4 ms, Hardwood dt=4 122 ms, Hardwood dt=1 425 ms, Hardwood pinned 1-core 537 ms, Parquet Java (single-threaded) 1777 ms.
The relative shape is similar to the m7i.2xlarge results, but the Threadripper is much faster.
In the single-core comparison, Hardwood is about 3x faster than Parquet Java in both cases: 32.0 ms versus 97.9 ms for the selective scan, and 537 ms versus 1777 ms for the match-all scan.
With multiple decoder threads, Hardwood is much faster again. The best Threadripper result is 8 decoder threads: 5.1 ms for the selective scan and 80.4 ms for the match-all scan.
Some extra benchmarks
I hacked on Gunnar’s benchmark code to add some more test cases.
Column subset - 7 numeric columns
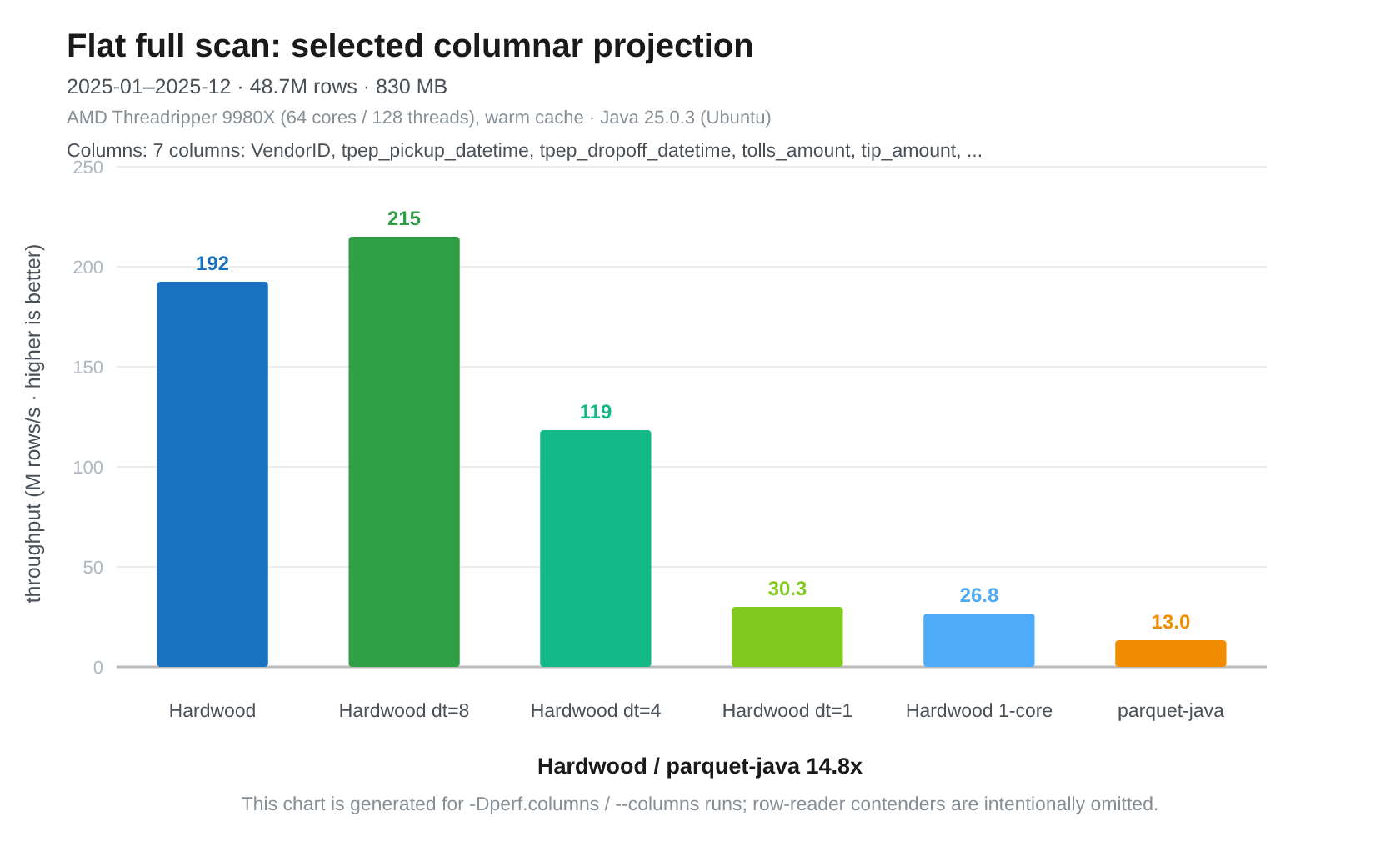
Fig 7: Threadripper. Hardwood (all cores) 192M/s, Hardwood dt=8 215M/s, Hardwood dt=4 119M/s, Hardwood dt=1 30.9M/s, Hardwood pinned 1-core 26.8M/s, Parquet Java (single-threaded) 13M/s
This is one of the clearest decoder thread scaling results. Hardwood 1-core is about 2x faster than Parquet Java, and 8 decoder threads reach 215M rows/s (14.8x faster than Parquet Java). Unlike the full-scan benchmarks, there is a large gap between 4 and 8 decoder threads here.
Column subset - 1 numeric, 1 string column
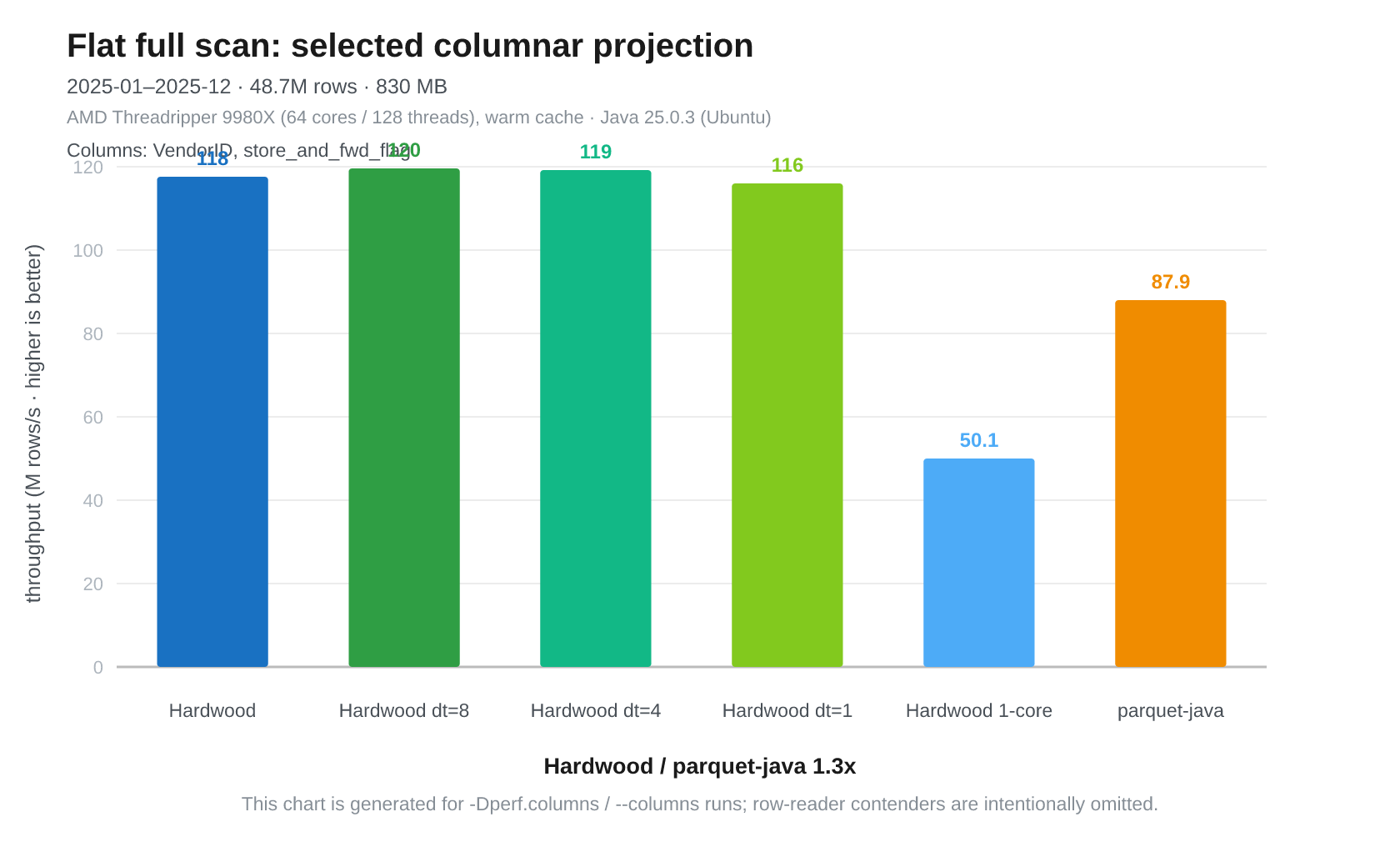
Fig 8: Threadripper. Hardwood (all cores) 118M/s, Hardwood dt=8 120M/s, Hardwood dt=4 119M/s, Hardwood dt=1 116M/s, Hardwood pinned 1-core 50.1M/s, Parquet Java (single-threaded) 87.1M/s.
The string column seems to change the performance profile. This case behaves differently, with Parquet Java winning compared to the pinned 1-logical-core Hardwood test. More than one decoder thread does not help: the unpinned Hardwood results are all between 116M and 120M rows/s. I haven’t profiled this so I can’t explain the result.
Custom Filter Predicates
In this test, we use the predicate amount < 100 AND category < 5, which matches 500324 rows (1%) of the deterministically generated 50M row dataset. This time the files are not clustered by the predicate but the total number of matching rows is 5x smaller than the filter test from earlier.
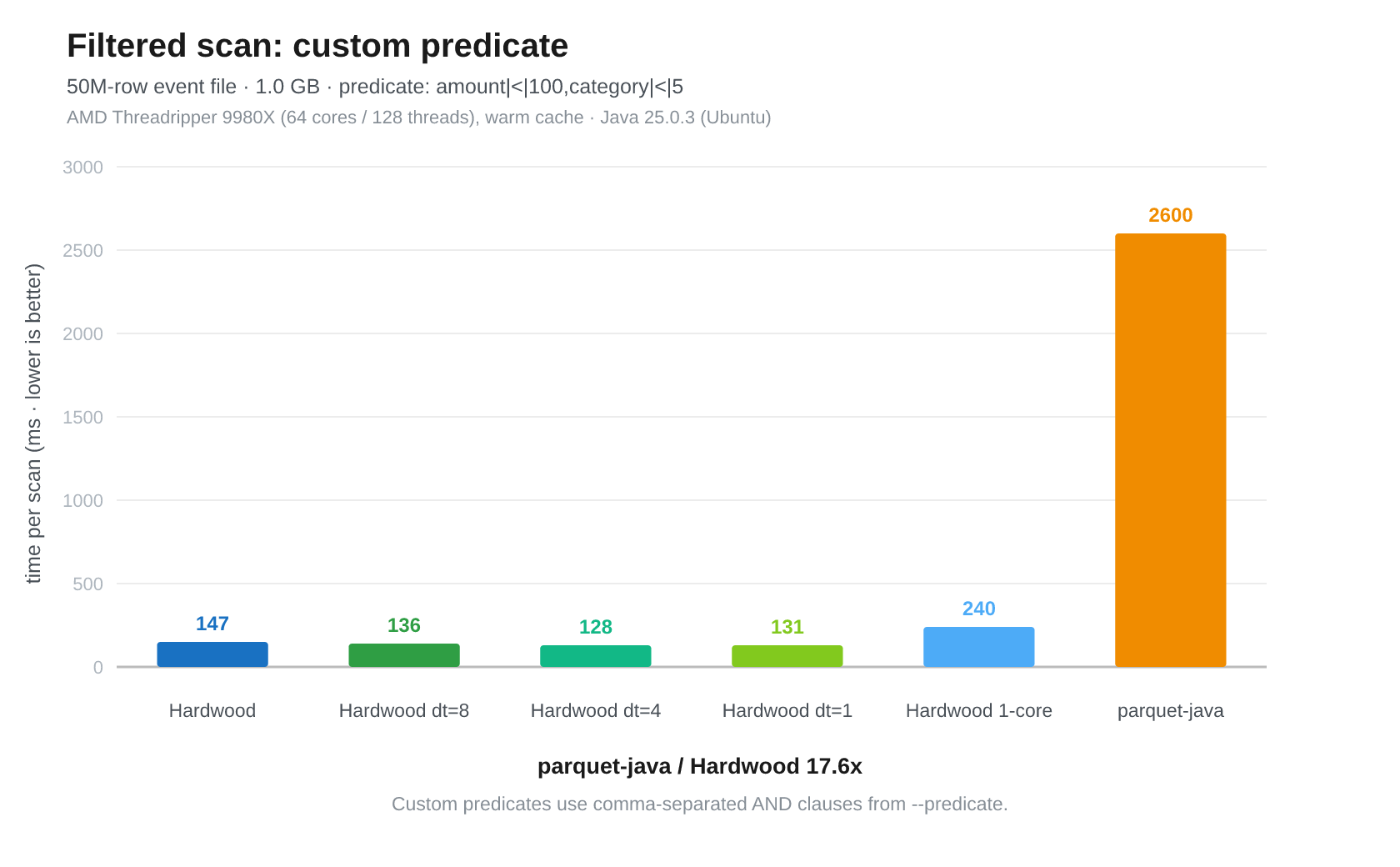
Fig 9: Threadripper. Hardwood (all cores) 141 ms, Hardwood dt=8 135 ms, Hardwood dt=4 131 ms, Hardwood dt=1 129 ms, Hardwood pinned 1-core 291 ms, Parquet Java (single-threaded) 2522 ms.
Hardwood is far ahead of Parquet Java here. Even the pinned 1-core Hardwood result is about 8.7x faster than Parquet Java. I ran the benchmark with the --gate flag, which verifies that each test returns the same data, and it passed, so the result looks legit.
Decoder threads do not help much in this test. The unpinned Hardwood results are all between 129 ms and 141 ms. That suggests this benchmark is limited by something other than parallel decoding.
Scaling out Hardwood processes
The Threadripper 9980X is a workstation, not a server. It has a higher clock speed but lower memory bandwidth that its EPYC server counterparts. I imagine you’d see lower performance numbers on the EPYCs for these tests, but the EPYCs would easily beat the Threadripper on the amount of parallel Hardwood workloads due to the 12-memory lanes compared to the Threadripper’s 4 lanes.
Thinking about memory bandwidth, I decided to see how Hardwood scales across instances, where each benchmark process was pinned to 4 physical cores and given 4 decoder threads.
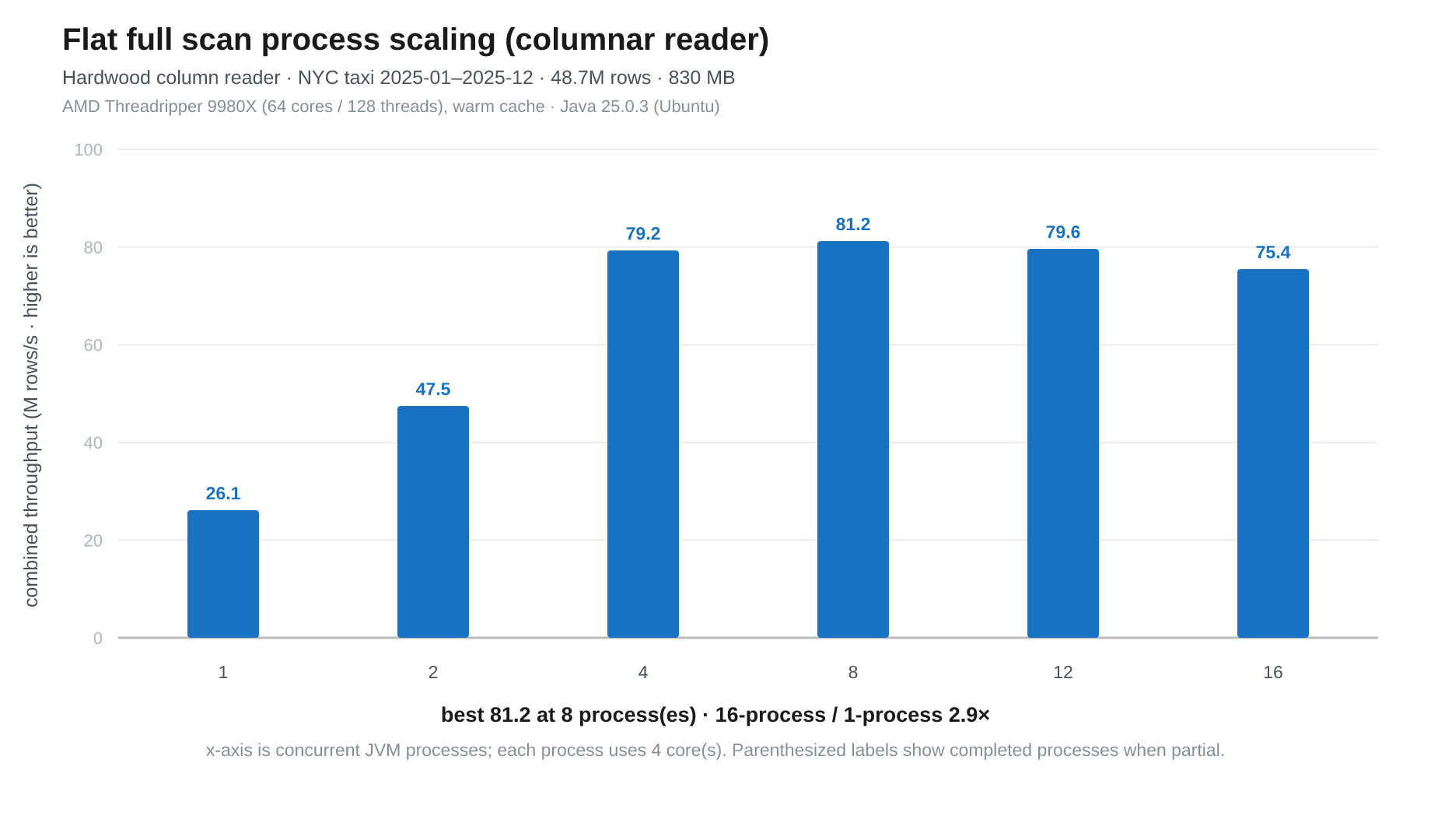
Fig 10. Threadripper. 1 process (4 physical cores) 26.1M/s, 2 processes (8 physical cores) 47.5M/s, 4 processes (16 physical cores) 79.2M/s, 8 processes (24 physical cores) 81.2M/s, 12 processes (48 physical cores) 79.6M/s, 16 processes (64 physical cores) 75.1M/s.
We reached close to this workstation’s memory bandwidth limit at 4 processes on 16 physical cores, and after that there was little benefit or even reduced throughput as efficiency dropped.
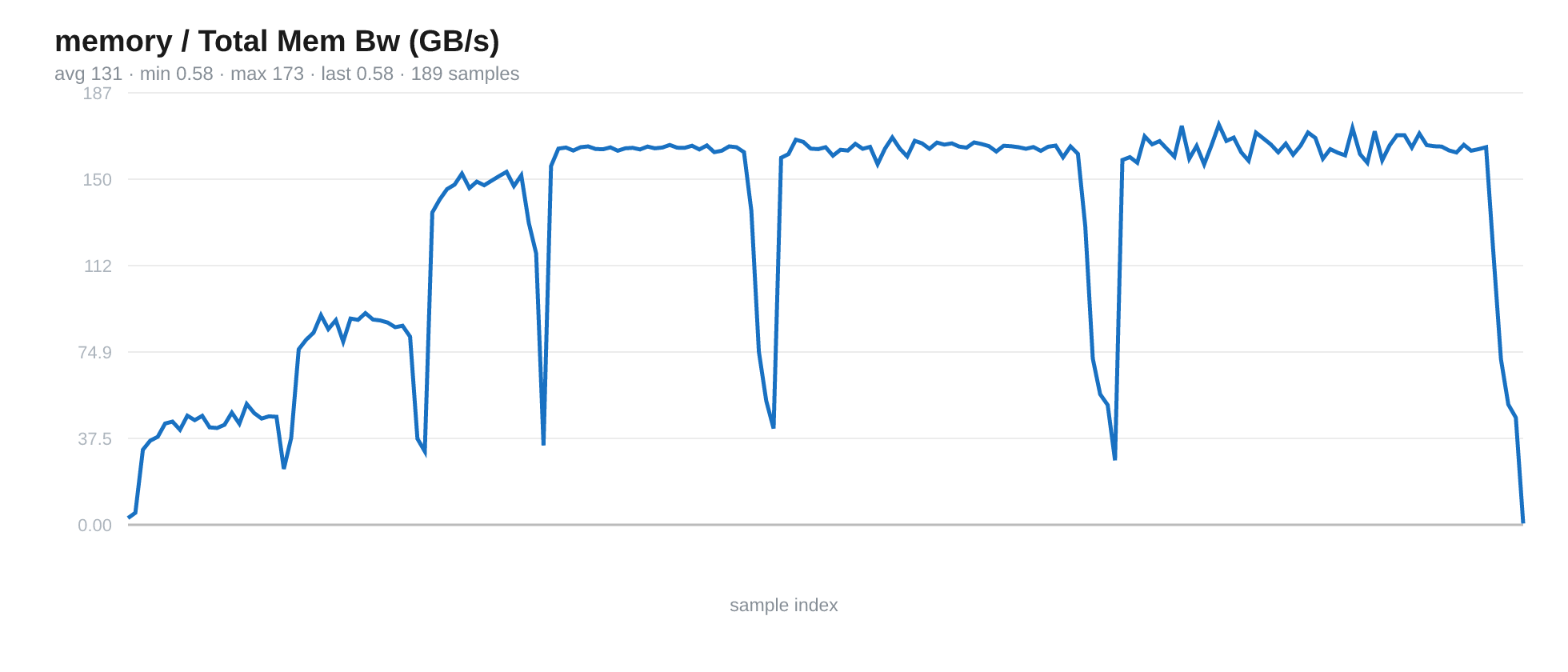
Fig 11. The memory bandwidth topped out in the 4th test (8 processes, 32 physical cores)
The Instructions Per Cycle (IPC) dropped further and further, signalling the reduced efficiency.
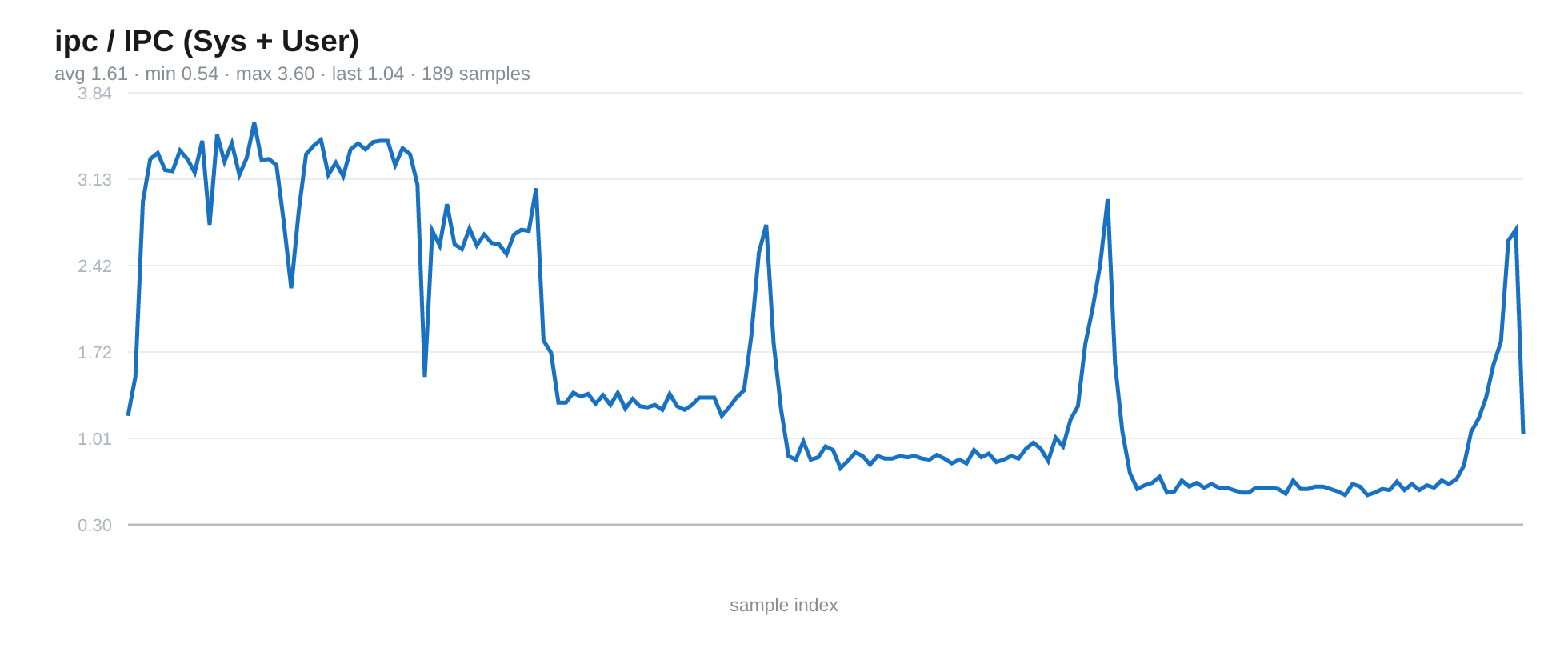
Fig 12. The IPC drops as we add more and more parallel benchmark instances.
And, we became increasingly memory bound.
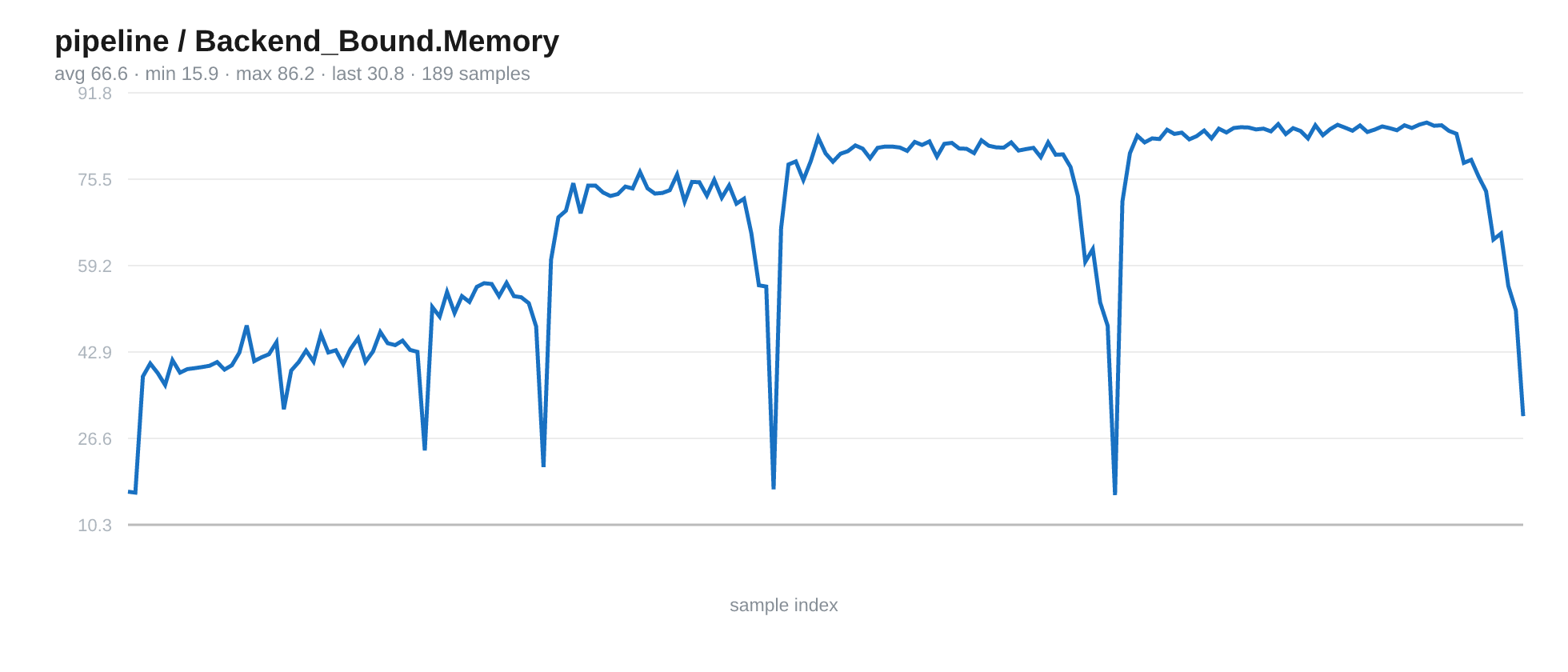
Fig 13. AMD uProf’s top-down estimate of how much CPU pipeline capacity is lost because the backend is waiting on the memory subsystem
The EPYC 9575F single socket has 614 GB/s (theoretical) and the dual-socket up to 1.2 TB/s (theoretical) bandwidth, compared to just 205 GB/s theoretical for my workstation (though the max actual I’ve measured is 170 GB/s). So the EPYC would have blown the socks off my workstation.
I’m including this as a reminder that benchmarks don’t usually measure things like memory bandwidth saturation under high parallel load.
Summary
On my Threadipper 9980X, Hardwood’s single-core performance looks strong against Parquet Java across most of these benchmarks. In the full columnar scan, pinned 1-core Hardwood is almost 2x faster than Parquet Java. This contrasted to the m7i.2xlarge where Hardwood only saw a modest single-core advantage over Parquet Java for this specific test. Thus a reminder that your mileage may vary.
In the positional row-reader scan, Hardwood was about 3.6x faster than Parquet Java, and in the filtered scans, about 3x faster. The custom predicate benchmark shows an even larger gap.
Hardwood’s multi-threaded performance is also strong up to a certain decoder-thread count (which is workload-hardware-dependent). On this Threadripper, 4 or 8 decoder threads were usually enough. The default Runtime.getRuntime().availableProcessors() value gives a ridiculous 128 decoder threads which was unsurprisingly less efficient than 8.
The main exceptions to decoder thread scaling were the named-column row reader, the string column subset, and the custom predicate benchmark. Those cases showed little or no benefit from increasing decoder threads, even when Hardwood still beat Parquet Java overall.
I initially wondered if the strong single-thread performance compared to the m7i.2xlarge was the Threadripper’s strong AVX-512 support, but after profiling it with AMDuProfPcm, it turned out that this was not the case. I also tested out enabling the Vector API, but it made no difference to the performance. If any performance engineers out there want a fun project, then my feeling is that Hardwood still leaves a lot on the table for optimizing. It could be a fun project.
I finish by saying this benchmarking was for fun on a workstation. So these results are not generalizable but they do correspond to the m7i.2xlarge results (just better). They are mostly useful as a directional look at how Hardwood behaves on a high-core-count workstation. You need to benchmark your own use case, on your chosen hardware.