In part 1, we described distributed computation as a graph and constrained the graph for this analysis to microservices, functions, stream processing jobs and AI Agents as nodes, and RPC, queues, and topics as the edges.
For a workflow to be reliable, it must be able to make progress despite failures and other adverse conditions. Progress typically depends on durability at the node and edge levels.
Reliable Triggers and “Progressable” Work
Reliable progress relies on a reliable trigger of the work and the work being “progressable”.
Reliable Progress = Reliable Trigger + Progressable Work
Progressable Work is any unit of work that can make incremental, eventually consistent progress even in the face of failures. Typically, a reliable trigger causes a repeated attempt at performing the work, which may include one or more of the following patterns:
Implements idempotency (so repeated attempts don’t cause duplication or corruption).
Durably logs partial progress, so it can resume from where it left off (thereby avoiding duplication or corruption).
Work that is atomic (via a transaction) is also helpful for consistency, though idempotency is also required to avoid duplication. Transactions may not be an option, and so reliable eventual consistency must be implemented instead (via progressable work).
Progressable work is work that is safe to retrigger, rewind, or resume.
But what re-triggers the work? This is where source state durability is required. The thing that triggers the work, and its associated state must also be reliable and therefore durable. The classic reliable trigger is the message queue.
So, summarizing, if we look at any given node in the graph, the reliability stems from:
A Reliable Trigger. This will require a form of durability.
Progressable Work. Either:
No controls, as duplication or inconsistency doesn’t matter.
Idempotency of tasks, so a re-triggering avoids duplication/inconsistency.
Transactions. Usually only available (or desired) from a single data system, such as a database. Still relies on idempotency to avoid duplication.
Durable logging of work progress, with the ability to resume where it left off (by caching intermediate results).
Some mix of the above.
Reliable progress in Stream processing
A stream processing job, such as Flink or Kafka Streams, ensures reliable progress by durably logging its progress via state persistence/changelogs (Progressable Work) and relying on a durable data source (Reliable Trigger) in the form of a Kafka topic.
Reliable progress in microservice / FaaS functions
A reliable function will have a Reliable Trigger and implement Progressable Work.
A reliable trigger for a function/microservice will be an RPC or a message (event/command) from a queue or topic.
Queues and topics are highly available, fault-tolerant, durable middlewares (and therefore great as reliable triggers). A queue durably stores messages (events or commands) until deleted. A message can trigger a function, and the message is only deleted once the function has successfully run. A message on a topic is basically the same, except that messages can be replayed, adding an additional layer of durability. Note that some queues can also do replay.
RPC is not innately reliable, it depends on the caller being available to maintain state in memory and reissue the RPC if a retry is needed. In typical microservices/functions, the function instance is not fault-tolerant, so it cannot do that.
For RPC to become innately reliable, it must also be “delivered” via a highly available, fault-tolerant, durable middleware. This is one of the roles of the Durable Execution Engines (DEE), and we’ll refer to RPCs mediated by these engines as Reliable RPC.
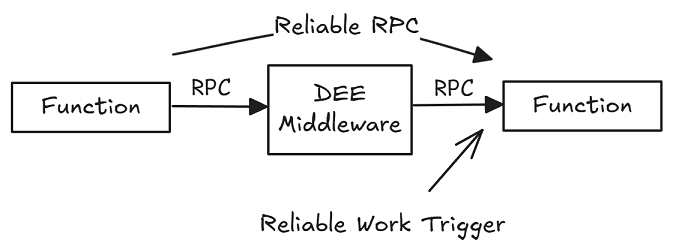
Progressable work, as already described, has two main options: idempotency or durable logging of work progress (and transactions can play a role for consistency).
Reliable progress in AI Agents
AI agents will become more deeply embedded in distributed systems as the category gains traction, with agents taking actions, calling APIs, and generating decisions. The need for reliable progress applies here too. Like any other node in a distributed workflow, an AI agent’s actions must be triggered reliably and either complete successfully or fail in a way that can be handled.
Many durable execution start-ups are now focusing on AI agents as a core use case. The Flink AI Agent sub-project (see FLIP-531) has also been spurred by the need for agents to progress reliably through a series of actions. Its approach is to treat AI inference and decision-making as part of the dataflow, with exactly-once semantics, checkpointing, and state management taken care of, in part, by Flink’s existing progressable work infrastructure.
Coordinated Progress of Workflows
So far, we have described distributed computation as a graph and constrained the graph for this analysis to microservices, functions, stream processing jobs, and AI qgents as nodes, and RPC, queues, and topics as the edges. Secondly, we have identified reliable progress as the combination of Reliable Triggers and Progressable Work (where durability plays a key role).
Reliable Progress = Reliable Triggers + Progressable Work
Now, we will examine work that spans multiple nodes of the graph, using the term 'workflow'. A critical aspect of workflow is coordination.
A workflow forms a graph of steps, where each node or edge in the graph can fail in unique ways. A failure may be simple, such as a service being unavailable to invoke, or complex, such as a partial failure where only half of the action was taken, leaving the other half undone (and inconsistent).
If we imagine a continuum, at each extreme we find a different strategy for coordinating such a workflow:
Use a decentralized, event-driven, choreography-based architecture.
Use a centralized, RPC-heavy, procedural orchestrator.
Coordination via Choreography
Key traits:
Decentralized coordination.
Reactive autonomy.
Coordinated by asynchronous events.
Decoupled services.
Event-driven choreography supports workflow in multiple ways:
Events act as reliable triggers. Only once an event has been fully processed will it become unreadable (by an offset advancing in Kafka or an event being deleted from a queue). If a failure occurs during the processing of an event, then the event remains to be consumed again for a retry.
Asynchronous: Consuming services do not need to be available at the same time as publishing services, decoupling the two temporally, increasing reliability.
Events can be replayed. Even processed events can be replayed if necessary (given the event streaming service supports that).
Events trigger rollbacks and compensations (sagas). If an error occurs, a service can emit a failure event that other services can subscribe to, in order to perform rollbacks and compensation actions. Kafka transactions support advancing the offset on the input topic and publishing an error event as an atomic action.
Long-running workflows. The workflow can pause and resume implicitly, based on the timing of published events. However, said timing is not typically controlled by the event streaming service.
Reliable event consumers must implement Progressable Work in some way, with idempotency being a common one.
Event-driven choreography pros and cons
While I list decoupling as the main pro, its impact cannot be understated.
Pros:
Highly decoupled services (a very big deal)
Independent service evolution and deployment (design-time decoupling).
Limited blast radius during failures (runtime decoupling).
Downstream services that execute subsequent workflow steps do not need to be available when the current step executes (temporal decoupling).
Highly adaptable architecture.
Scales naturally with system growth. New consumers can react to events without requiring changes to existing publishers.
Flexible composition. Workflows can evolve organically as new consumers are added, enabling emergent behavior.
Cons
Reasoning about complex flows
Hard to reason about for complicated workflows or sprawling event flows.
It can be challenging to find where a choreographed workflow starts and where it ends, particularly as it crosses team boundaries.
Ownership of the workflow is distributed to the participating teams.
Monitoring and debugging
It can be difficult to debug the workflows that cross many different boundaries.
Monitoring workflows is challenging due to its decentralized and evolvable nature.
Consistency challenges
Compensations can be harder to reason about as logic is spread across consumers, making it sometimes challenging to verify full undo/compensation without strong observability.
Non-deterministic execution: more likely to see race conditions (such as receiving OrderModified before OrderCreated).
No in-built Progressable Work tooling, only reliable triggers.
Developer training
Developers must learn event modelling.
Developers may need to learn how to use Kafka or a queue reliably (or use a high-level framework).
Coordination via Orchestration
Key traits:
Centralized coordination.
Procedural control.
RPC triggers subordinate microservices/functions.
Well-defined scope.
Workflow with orchestration engines
“Orchestration engines” refers to DEEs such as Temporal, Restate, DBOS, Resonate, LittleHorse, etc, which all have slightly different models (which are out of scope for this document).
An orchestrated workflow is a centrally defined control flow that coordinates a sequence of steps across services. It behaves like a procedural program.
Procedural code. The orchestrated workflow is written like regular code (if-then-else).
Progressable Work via durable logging of work progress. State is persisted so it can survive restarts, crashes, or timeouts, and can resume based on timers. This is key for completing sagas.
Reliable Triggers via reliable RPC (if the framework supports that) or events (can integrate with event streams).
Centralized Control Flow. Unlike choreography, where each service reacts to events, orchestration has one logical owner for the process: the orchestrator.
Explicit Logic for Branching, Looping, and Waiting. This may use regular code constructs such as in Function-based Workflow, or may use a framework SDK for these Ifs and Loops in Graph-based Workflow.
Long-running workflows. An orchestrated workflow can pause, and then resume based on 1st class triggers or timers.
An orchestrated workflow is like a function, and therefore, it needs its own Reliable Trigger and the orchestration code must implement Progressable Work.
A reliable trigger of the workflow itself could be:
An event or command delivered via a queue or topic.
A Reliable RPC mediated via a Durable Execution Engine.
Progressable work could be implemented entirely via idempotent steps (though this may not be practical as a general rule as idempotency can be hard to implement). Therefore, the durable logging of work progression (by a Durable Execution Engine) can add value.
Orchestration-engine pros and cons
Pros
Centralized control flow makes it:
Simpler to reason about.
Easier to monitor and debug.
Reliable:
Reliable Triggers and Progressable Work are built into DEE frameworks.
Reliable RPCs can function without temporal coupling (via DEE).
Compensation actions are clearly linked to failures and made reliable.
Cons
Challenging to version. It can be hard to update workflows while supporting existing workflow executions. Long-running workflows could conceivably have multiple versions running concurrently.
The orchestration (or DEE) service is another infrastructure dependency.
Orchestration code belongs to one team, but that team must coordinate with teams of the subordinate microservices.
Coupling
Orchestration can lead to tighter coupling without discipline. This can conflict with microservices autonomy and bounded context independence.
Greater design-time coupling leads to more versioning as flows change.
Developer training:
Developers must learn the programming model of the specific DEE (all are a bit different).
Developers must learn about deterministic workflow execution, step vs workflow boundaries and avoiding anti-patterns such as God workflows which control everything.
Direct vs Indirect Edges
In Part 1, I described how not all edges in a workflow graph are equal. Some are direct dependencies which are essential steps that must succeed for the business goal to be achieved. For example, the edge from the Order Service to the Payment Service during checkout is part of the core execution path. If it fails, the workflow fails.
Other edges are indirect. These represent auxiliary actions triggered by the workflow, such as updating a CRM, reporting service or auditing. While important, they are not critical to completing the core task itself. Often these just need to be reliable, but are triggered in a decoupled and one-way fashion.
In orchestration, these distinctions matter. A well-designed orchestrator should focus only on the minimal set of steps required to drive the business outcome (the direct edges). Incorporating indirect actions directly into the orchestrator increases coupling, inflates the workflow definition, and introduces more reasons to redeploy or version the orchestrator when non-essential concerns change.
Choreography, by contrast, treats direct and indirect edges the same. Events flow outward, and any number of services can react. There is no centralized control, and thus no enforced boundary around what "belongs" to a given workflow. This can be both a strength (such as encouraging extensibility) and a weakness. The main weakness being that it is harder to reason about what constitutes the workflow's critical path.
Choreography vs Orchestration Summary
Choreography and orchestration are both essential patterns for coordinating distributed workflows, but they offer different properties. What they share is the need for durability in order to provide reliability.
Orchestration looks promising for mission-critical core workflows because of its superior understandability, observability, and debuggability. With a centralized control flow, durable state, and explicit compensation handling, orchestration frameworks make core workflows easier to understand, monitor, and debug. The orchestration engine provides Reliable Trigger and Progressable Work support. But such orchestration should be limited to islands of core workflows, connected by indirect edges in the form of events.
Choreography, on the other hand, is indispensable for decoupling systems, allowing services to react to events without tight coupling or centralized control.
Design-time decoupling enables teams to build, deploy, and evolve services independently, reducing coordination overhead and supporting faster iteration.
Runtime decoupling minimizes blast radius by isolating failures — one service can fail or degrade without directly affecting others.
Temporal decoupling allows producers and consumers to operate on different schedules, enabling long-running workflows, asynchronous retries, and increased resilience to transient outages.
Together, these forms of decoupling promote architectural flexibility and team autonomy. Events act as Reliable Triggers, and the event consumers must decide how to implement Progressable Work themselves.
Hybrid workflows
In practice, many operational estates could benefit from a hybrid coordination model. There are two types of hybrid:
Mixing choreography and orchestration across the graph. As I already described, orchestration should not control the entire execution flow of a system. Unlike choreography, which can span an entire system due to its decoupled nature, orchestration should focus on well-defined processes. These orchestrated workflows can still integrate with the broader choreographed system by emitting events, responding to events, and acting as reliable islands of control within a larger event-driven architecture.
Using orchestration via events (or event-mediated orchestration). In this hybrid model, the orchestration code does not use RPC to invoke subordinate microservices, but sends commands via queues or topics. Subordinate microservices use the events as Reliable Triggers, implement their own Progressable Work, and send responses to another queue/topic. These responses trigger the next procedural set of work. In this model, Reliable Triggers are handled by queues/topics, and Progressable Work is either done via idempotency or durable logging of work progress. This can avoid the need for a full DEE, but might require custom durable logging.
Next up
Now that we have the mental model in place, Part 3 will refine the model further, with concepts such as coupling and synchrony.
Coordinated Progress series links: