This is the first of a number of posts looking at log replication protocols, mainly in the context of state machine replication (SMR). This first post will look at a log replication protocol design called Virtual Consensus from the paper: Virtual Consensus in Delos.
In 2020, a team of researchers and engineers from Facebook, led by Mahesh Balakrishnan, published their work (linked above) on a log replication design called Virtual Consensus that they had built as the log replication layer of their database, Delos.
As an Apache BookKeeper committer (non-active), I immediately saw the similarities to BookKeeper. Yet, the Virtual Consensus paper went further than BookKeeper, describing clean abstractions with clear separations of concerns. Just as the Raft paper has helped a lot of engineers implement SMR over the last 10 years, I believe the Virtual Consensus paper could do the same for the next 10. There are a few reasons to believe this that I will explain in this post.
Motivation for this post
I decided to write this post because Mahesh Balakrishnan (the lead researcher/engineer of the Virtual Consensus work at Facebook) came to Confluent as a researcher and set about designing a Kafka engine designed around Virtual Consensus. I remember my first meeting with Mahesh where he described the project. I didn’t know his background at the time, and I remarked stupidly, “It sounds like you are describing Delos. Do you know the paper?” and my colleagues laughed pointing out that he was the lead author. Anyway, suffice to say I was excited about the prospect. The work to add a Delos-style of replication in Kora began in the beginning of 2022, and this week, his team’s work was made generally available in AWS in its initial form as Freight Clusters.
I want to write a bit about this new architecture inside Kora (the multi-tenant serverless Kafka engine inside Confluent Cloud), as well as some topics such as disaggregation of replication protocols and the impact of cloud object storage. This is all too much for one post, so I’m going to divide and conquer and write several blog posts to cover it. I decided a good place to start is looking at Virtual Consensus in Delos.
Virtual Consensus (Delos)
The paper Virtual Consensus in Delos introduces the idea of Virtual Consensus via the Virtual Log and Loglet abstractions. I’m hesitant to call Virtual Consensus a protocol because the paper is not overly prescriptive. I think of it as a set of abstractions with associated responsibilities that act as a framework for building your own log replication protocol to fit your specific needs.
The virtual log is an abstraction that applications, such as databases, can use without being coupled to the specific consensus implementation. This by itself is not new; after all, we could wrap a Raft implementation in a generic abstraction. A key contribution of Delos is the Loglet abstraction, which hides the data plane behind a simple API. A loglet is an abstraction for independent log segments.
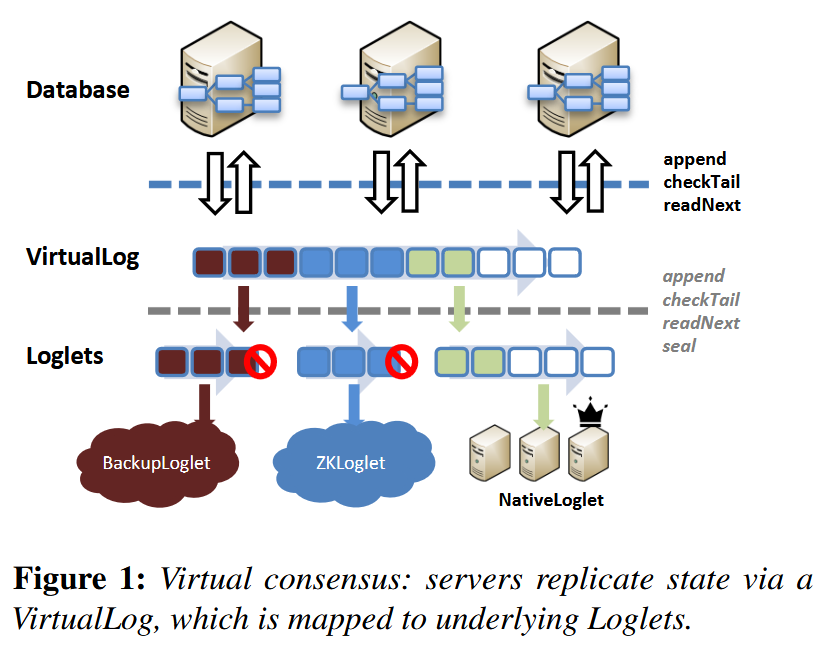
From Virtual Consensus in Delos. Shows database servers, in their role as the state-machines, sitting above the Virtual Log abstraction.
This segmented log is composed of a chain of independent log segments, where each log segment is itself a log. The segments are independent because each has no knowledge or dependency on the other. Delos calls each log segment a Loglet and chains Loglets into what it calls a shared log. The term “shared log” is used because of how Delos layers state-machine protocols on top of a single log, but that is not the focus of this post.
Fig 1. The shared log, formed by a chain of loglets,
Virtual Consensus uses a virtual sequential address space for the shared log and maintains a mapping of this virtual address space to the individual log segments.
Fig 2. Virtual address space maps onto loglets
The Virtual Log’s responsibilities include:
Providing a single address space for the log (that underneath maps to loglets).
Acts as a router for append and read commands, forwarding the command to the appropriate loglet. Writes always go to the active loglet.
Chaining loglets to form an ordered log.
Reconfiguring the log under failure scenarios for fault-tolerance and high availability.
Each loglet must:
Durably store an ordered sequence of entries (usually with redundancy).
Respond to seal and checkTail commands from the Virtual Log (more on that later).
Be fast (the loglet is in the critical data path).
“In virtual consensus, we divide and conquer: consensus in the VirtualLog is simple and fault-tolerant (but not necessarily fast, since it is invoked only on reconfigurations), while consensus in the Loglet is simple and fast (but not necessarily fault-tolerant).”
Separation of concerns
We can broadly split up the work (and consensus) needed to maintain an ordered, replicated log into control and data planes. There are more ways of disaggregating a protocol, which I will cover in a follow-up post, but for today, we’ll focus on control plane-data plane separation.
“Virtual consensus also simplifies the development of new
consensus implementations. Virtualization splits the complex
functionality of consensus into separate layers: a control plane
(the VirtualLog) that provides a generic reconfiguration capa-
bility; and a data plane (the Loglet) that provides critical-path
ordering. While the VirtualLog’s reconfiguration mechanism
can be used solely for migrating between entirely different
Loglet implementations, it can also switch between different
instances of the same Loglet protocol with changes to lead-
ership, roles, parameters, and membership. As a result, the
Loglet itself can be a statically configured protocol, without
any internal support for reconfiguration. In fact, the Loglet
does not even have to implement fault-tolerant consensus (i.e.,
be highly available for appends via leader election), as long as
it provides a fault-tolerant seal command, which is theoreti-
cally weaker and practically simpler to implement.”
Generically, a log replication data plane is mostly about the operations to ensure data redundancy and some responsibility for maintaining the strict order of operations. It does the steady state work (and a system should be in steady state most of the time).
Generic data plane responsibilities:
Redundancy: Replication, erasure-coding or making API calls to someone else’s redundant data storage service (like object storage).
Storage: Physical storage on drives (if not using someone else’s storage service).
Ordering: Ensuring the the strict ordering of operations.
The generic control plane is mostly about providing fault-tolerance by reacting to failure, and also performing configuration changes based on policies or administrator commands.
Generic control plane duties:
Leader election (in leader-based protocols). If a leader goes offline, a new leader must be elected or the system becomes non-functional.
Membership changes. If a server fails completely, it will need to be replaced with another server, requiring a membership change.
Changing policies (such as retention).
Also bears some responsibility for maintaining strict ordering and durability of the log. For example, if it were to make a mistake in leader election or reconfiguration, it could cause inconsistency of the log itself.
In Virtual Consensus, the data plane consensus focuses on redundancy, while consensus in the control plane is focused on fault-tolerance (healing, heat management). These data and control plane consensus mechanisms are decoupled except for Loglet sealing, which is a fencing mechanism to prevent split-brain.
The steady-state is entirely data plane, but when policies fire or failures occur, the control plane kicks in to move the system from its current steady-state configuration to another. In Virtual Consensus, this is called reconfiguration.
Fig 3. Reconfiguration moves the system from one steady state configuration to another in response to failures, policy triggers or other factors such as load balancing.
The components behind the abstractions
The exact components depend on the system designers and loglet implementations. The paper is not overly prescriptive on how to break up the logic into components. Broadly, we can break things down into three components:
Client:
Co-located with the application (state-machine). In Delos, the client is integrated into the database server.
The client itself is stateless and can act in a leader-like role (see below).
Routes appends to the active loglet.
Routes reads to the appropriate loglet.
Initiates log reconfigurations and commits them to the metastore.
Metastore:
Control plane state.
A versioned register for storing the log metadata, such as the loglet chain, loglet metadata, and so on.
Loglet implementation
Data plane state.
Quorum-replication, object storage, databases, etc.
Fig 4. Under the Virtual Log abstraction, we have the Client, Metastore and Loglet Layer.
Unlike traditional consensus protocols (e.g., Paxos, Raft), where a designated server-based leader manages ordering and coordination, Virtual Consensus shifts some of these responsibilities to the client.
The client is responsible for:
Proposing commands to the loglet layer.
Initiating reconfigurations when needed.
Determining command ordering. The (leader) client can act as a sequencer, dictating the order in which requests are inserted into the virtual log. However, in some deployments, this role is handled by the underlying loglet implementation (with a dedicated sequencer component).
Consensus is separated into redundancy (Loglets) and fault-tolerance (VirtualLog). The cool thing about the Virtual Log consensus is that all the client really needs is a versioned register with conditional put semantics (such as an object storage blob) to commit configuration changes. That and also a fencing mechanism at the loglet layer (sealing loglets). You don’t need anything fancy, such as Raft or Paxos.
Loglets - Data plane
The Loglet is a log segment abstraction that abstracts the consensus protocol from the clients. For example, a Loglet implementation might be:
Backed by a database.
Backed by object storage.
Quorum-replicated over a number of storage servers.
Erasure coded over a number of storage servers.
Because of this loglet abstraction, the virtual log can comprise loglets of different implementations. There are a number of benefits of a log of heterogeneous loglets:
Loglet implementations can be chosen based on desired characteristics:
Quorum replicated (servers using SSDs) to provide durability with the lowest latency.
Erasure coded to provide a balance of cost and latency.
Object storage to provide the lowest cost. Different object storage tiers can easily be used in the same log. I.e. cold storage for oldest loglets, fast storage for most recent storage.
Converged local storage for local dev.
And so on…
Tiering, self-healing, and repair are separate concerns.
Background jobs can rewrite loglets from one type to another.
Background jobs can repair under-replicated loglets, or create object storage-based loglet backups.
Migrations from one type of consensus/backing storage to another can be done without downtime or significant risk.
A cool aspect of this abstraction is that while a specific loglet could be based on quorum replication, it can omit the more complex aspects of these protocols, such as leader election and reconfiguration. Instead, quorum replication protocols integrated into the Loglet abstraction only need to implement replication over a static set of nodes (vastly simplifying its logic). This is because the data plane is absolved of all control plane duties. That isn’t to say you can’t implement leader election, etc, you could plug in a Raft-based log service as a loglet implementation. The point is that you don’t have to.
Each Loglet offers a common set of functions (regardless of the underlying implementation):
append: appends an entry to the loglet returning a position in the log (of the loglet).
readNext: returns the next entry based on a position in the loglet.
checkTail: returns the next unwritten position of the loglet and whether the loglet is sealed or not.
seal: Prevents further writes to the loglet (fencing).
I’ll explain the role of checkTail and seal further down.
Virtual Log - Control plane
“The VirtualLog is the only required source of fault-tolerant consensus in the system, providing a catch-all mechanism for any type of reconfiguration. The Loglet does not have to support fault-tolerant consensus, instead acting as a pluggable data plane for failure-free ordering.”
The Virtual Log stitches together independent loglets. A new loglet may be appended when:
The active loglet experiences a failure, entering a degraded state.
The active loglet has been sealed.
System load patterns require a new loglet with a different cohort of backing servers (such as in the case of a quorum-replicated loglet).
Policies such as maximum loglet size (plausibly, this is not discussed in the paper).
In the case of a quorum-replicated loglet, if a backing storage server goes offline, the virtual log can decide to seal the active loglet (fencing it from further writes), then create and append a new active loglet with a different cohort of storage servers. This is a reconfig-extend operation as it extends the log with a new loglet.
Fig 5. A reconfiguration with a quorum-replication loglet implementation. Now that Loglets 1 and 3 are under-replicated because of the loss of server 9, the virtual log will also have to perform reconfig-modify operations to replace server 9 in those loglets to restore the correct level of redundancy.
In the example above, none of the loglets must reconfigure themselves. They must only be capable of responding to seal commands to prevent further writes–often known as fencing. The nature of how a loglet implements the seal command is loglet specific. I will provide an example in another post based on the Delos NativeLoglet.
The Virtual Log has three reconfiguration functions:
reconfigExtend: Extends the log with a new loglet.
reconfigModify: Reconfigures an existing loglet (such as repairing a degraded loglet by replacing a failed server).
reconfigTruncate: Used for trimming the log suffix (garbage collecting the log).
Repairing a sealed loglet, via a reconfig-modify op, is not fraught with the complexity of a reconfiguration in Raft. In Raft, we’re reconfiguring a live log that is being actively written to. A sealed loglet is static and a repair can be as simple as copying the data to a new server and updating the metadata.
In static quorum replication (or erasure-coded) loglets, the work of performing a reconfiguration is balanced between the virtual log and the loglet implementation (as choosing a new write-set of a loglet is implementation specific).
“In the case where the Loglet operates within a static configuration and relies on the VirtualLog for any form of reconfiguration, it reacts to failures by invoking reconfigExtend on the VirtualLog, which seals it and switches to a different Loglet. In this case, each Loglet is responsible for its own failure detection, and for supplying a new Loglet configuration minus the failed servers. In other words, while the VirtualLog provides the mechanism for reconfiguration, Loglets are partially responsible for the policy of reconfiguration.”
Choosing a new configuration for a new loglet, that is independent of the last loglet, is vastly more simple than a log implementing safe leader election and membership changes. As is repairing a sealed loglet. Some of that complexity can move to the seal command, in the case of quorum-replicated loglets, though it is still far less complicated.
Log Reconfiguration for fault-tolerance
In steady state:
The client is directing writes to the active loglet (data plane only). The loglet ensures data redundancy for durability.
The loglet chain remains unchanged and thus no metadata must be updated.
The active loglet metadata has a starting position (in the main log), but no end position (which is determined when it is sealed). The client knows the end position, but the client is stateless, and this information is only updated durably after sealing.
The vast majority of the time, the active loglet is doing all the work. However, in the case of a failure, or some policy-driven trigger, the client kicks in to reestablish steady-state in a new configuration (a reconfiguration).
At a high level, reconfiguration is dead simple and exercised by the client (within the Virtual Log abstraction). It could be the existing client, or even be a new client after a fail-over due to the original client becoming unreachable. The high-level steps are:
Seal the active loglet.
Call checkTail on the sealed loglet to learn of the last committed entry (its end position).
Create a new loglet as the active loglet.
Commit the operation by writing a new version of the log metadata, which includes:
The sealed loglet metadata (now with an end position and sealed status).
The virtual to loglet address mapping.
The metadata of the new loglet.
The loglet chain with the new loglet appended to it.
Two clients can battle each other for control, competing to seal and create new loglets and append them to the chain. However, safety is guaranteed by the combination of loglet sealing and conditional puts to the metadata.
Underneath the loglet API, the append, seal, and checkTail command implementations can be relatively simple or more complex, though that is hidden from the virtual log. The NativeLoglet is very similar to BookKeeper; it uses quorum-based replication and a quorum-based seal mechanism–once a quorum of storage servers of the loglet have set the seal bit, the seal operation is complete. We know that no other client could make successful writes to the loglet.
The client
What is the client in this Virtual Consensus protocol? There is a great deal of flexibility here; the paper is not overly prescriptive. I will give a couple of examples.
Pulsar/BookKeeper example
Apache Pulsar, in combination with Apache BookKeeper, shares a lot of common ground with the NativeLoglet implementation in Virtual Consensus. Pulsar brokers act as the client of the log storage layer (BookKeeper). Pulsar uses the Managed Ledger abstraction, which is akin to the Virtual Log. The Managed Ledger module acts as the client, performing writes to the active log segment in BookKeeper, reconfiguring the log to extend it with new BookKeeper segments, and so on.
Fig 6. The Pulsar/BookKeeper architecture is akin to a specific implementation of Virtual Consensus.
Each topic partition has one leader (a broker). If a broker fails, another broker assumes ownership of the partition. This is coordinated via ZooKeeper/Oxia. To assume leadership, the Managed Ledger module of the broker seals the active log segment and performs a reconfigure-extend of the partition with a new segment. It commits the reconfiguration by performing a versioned write to ZooKeeper (or Oxia).
If the original broker is still around and still believes it is the leader of the partition, it would is prevented from writing to the active segment due to the segment sealing. The sealing prevents split-brain, and the conditional put to the metastore prevents lost reconfiguration. The two brokers could duel it out over the partition ownership, but none could cause data inconsistencies, only availability issues due to the constant reconfigure-extend battle.
Delos example
Delos is a leader-based distributed database at Facebook. A single leader replica appends writes to the Virtual Log, which it uses to ensure strict consistency across database replicas. Other replicas act as read replicas that can assume leadership if the leader were to fail. Each replica maintains a copy of the database state by applying the replicated commands of the Virtual Log.
Fig 7. Delos ensures strict consistency across database replicas by applying commands from the virtual log.
Within the Virtual Log, each Delos replica uses a client to direct writes to the loglet layer and perform reconfigurations. In the case of the Native Loglet, it has a sequencer component that the client of the leader-replica directs writes to. The sequencer assigns a position to each command and forwards the request to all LogServers.
Fig 8. The NativeLoglet uses a dedicated sequencer component within the loglet abstraction. Otherwise, we see similarities to Pulsar. One difference is that Delos maintain state with read replicas, whereas Pulsar brokers do not.
In a leader failover, the new Delos replica leader will seal the active loglet. In the case of the Native Loglet, it performs a quorum-seal operation very similar to Pulsar and BookKeeper.
There is a lot more nuance to how this stuff works so I’ll probably do a deep dive into that in the future.
Some of the benefits of the Virtual Consensus design approach
We can describe Raft as a unified, or converged, protocol because it combines the data and control planes into one tightly coupled protocol:
Each Raft server implements the whole protocol. Each server participates as a peer in consensus, replication, and storage.
Replication cannot be separated from consensus, they are woven together.
The replicated log mixes data plane and control plane entries.
There are drawbacks to a unified protocol:
High coupling: Because Raft combines control plane concerns (leader elections, reconfiguration) with data plane concerns (replication, with ordering), evolving the data plane cannot be done without also impacting the control plane. The control plane is even integrated into the log itself, with a mix of data and control entries. Changes to one plane necessitate changes to the other.
More complexity: the protocol is large with many operations that can interleave in complex ways.
Less flexibility: This point is best illustrated when you look at how flexible more disaggregated protocols can be. But we cannot do things like independently scale consensus and replication separately or use erasure coding instead of replication as two examples (I’m unconvinced by CRaft).
Segmented logs also have some benefits over monolithic logs:
Write-availability/adaptability:
Quorum-replicated monolithic logs cannot react to failures as flexibly or efficiently as a segmented log. If a server goes offline, either the log exists in a degraded state until the failed server comes back, or in the case of catastrophic failure, the log must be replicated to a new server.
Segmented logs can react to failures immediately by sealing the active segment and creating a new segment with a different write-set (without the failed server). Background repair operations kick in to repair degraded sealed segments (without impacting write-availability).
Data movement:
Monolithic logs must be actively moved to balance load across a cluster of servers. This is expensive in terms of CPU, storage IO, and network bandwidth.
Segmented logs allow for reconfiguring the log based on load distributions and hardware failures, without costly data movement. Simply seal the active segment and create a new segment across a different set of servers to balance the write load.
Segmented logs can use tricks such as aging out storage servers by marking them as read-only and waiting for retention policies to naturally empty the server of data until it can be switched off.
However, one big caveat to the above is tiered storage, which significantly reduces the size of the quorum-replicated log stored on servers. Aggressive tiering can massively reduce the cost of data movement of monolithic logs (which is what Kora has historically done to make heat management more efficient).
But even with storage tiering, the logical organization of logs into explicit segments (in metadata) make tiering cleaner and opens up optimizations such as:
Multi-level tiering (hot data, medium hot, cold etc).
Multiple representations per segment. For example, hot data can be aggressively tiered to S3 and remain available in its original quorum-replicated storage.
Simplified consensus
Finally, the thing I love about Virtual Consensus is that the virtual log consensus is so simple, relying on a versioned register, such as an object in an object store like S3. So many open-source and closed-source systems now rely on put-if-absent or other conditional puts of object storage. Lower-latency object storage tiers can make this consensus strategy even more viable.
If you combine that with an S3 Loglet, you just massively simplify the entire replication protocol. The Virtual Consensus abstractions truly allow you to pick your trade-offs in terms of cost, latency, complexity/simplicity (even in the same log). It is a design that can work perfectly in the cloud, running entirely on object storage or in higher-performance deployments based on quorum replication (using SSDs for storage) and a high-performance consensus service. I will explore this aspect further when I describe the new Kora internals in another post (plus the Kora engineering team will also do a deep dive).
I’m quite bullish on Virtual Consensus. I think it should probably considered first, before Raft, as it may provide a simpler and more flexible foundation for building distributed data systems.
What’s next to cover?
In subsequent posts I will try to cover (perhaps ambitiously):
A deep dive into the consistency of Virtual Consensus using the Native Loglet implementation.
How Pulsar and BookKeeper map onto Virtual Consensus, and where they differ.
A survey of replication protocols from the perspective of disaggregation and monolithic vs segmented logs.
A look at how Kora uses Virtual Consensus.