Get RabbitMQ consumer groups without the need for extra plugins or new server software.
This is the first post in a series that will look at bringing Kafka features to RabbitMQ - the first being RabbitMQ consumer groups. The consumer group messaging pattern provides many benefits over RabbitMQ's usual competing consumers pattern. The problem is that it takes more work to set up and the existing libraries do not support automatic queue-consumer assignment. In this post I'll introduce a client library that will work with existing RabbitMQ libraries to provide consumer group functionality including automatic queue assignment and rebalancing (modelled on the Kafka client libraries).
Kafka shards its topics into one or more partitions, and uses the consumer group pattern to assign consumers to partitions and performs rebalancing when partitions and/or consumer change.
We can map this onto RabbitMQ by using multiple queues which get routed to by a Consistent Hash exchange. The client library then performs consumer to queue assignment and rebalancing.
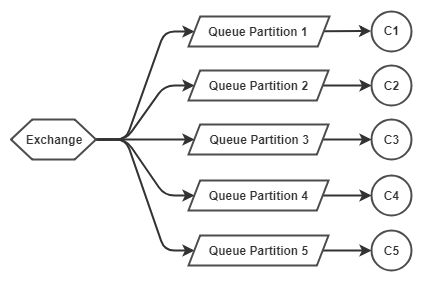
Fig 1. Messages partitioned across five queues, with one consumer per queue.
In the next post we'll take what we cover in this post about RabbitMQ consumer groups and put it into practice. We'll stand up a RabbitMQ cluster and run highly replicated services in Docker for publishing to and consuming from the RabbitMQ cluster.
I go into detail about these two message brokers in my RabbitMQ vs Kafka blog series and webinar, so check that out if you want to see how they stack up against each other.
First let's do a deeper dive into the consumer group pattern, looking at Kafka.
Learning From Kafka - Partitions and Consumer Groups
In Kafka, publishers send messages to a topic and consumers consume from that topic. A topic is comprised of one or more partitions. Each partition is a separate data structure where we get the same ordering quarantees as a single queue. Kafka's partitions allow it to scale out massively, a single topic could have hundreds or even thousands of partitions.
Consumer groups are groups of consumers that coordinate to consume the messages of a given topic (its partitions). One partition cannot be consumed by more than one consumer of the same consumer group.
Producers are responsible for choosing the partition they send each message to. The Kafka client libraries support two out-of-the-box options: round robin and hash based routing (based on the hash of the Record Id of the message). If you have no message ordering requirements then round robin in fine. When you need message ordering guarantees, then hash based routing is best (more on that below).

Fig 2. One topic, three partitions with three consumers.
We can have more partitions than consumers, meaning that consumers can consume from multiple partitions.
Fig 3. Five partitions with three consumers.
When there are more consumers than partitions, the extra consumers remain idle.
Fig 4. One consumer stays idle as one partition can only be read by one consumer of the same consumer group.
When a partition gets added, a consumer shutdown/dies or a new consumer comes online then rebalancing occurs. This is where all consumers stop consuming and get assigned one or more partitions again.
Fig 5. Rebalancing triggers after two new consumers come online.
And finally, consumers of different consumer groups do not tread on each others toes. Two consumers can consume the same partition, as long as they are members of different consumer groups.
Fig 6. Two consumer groups consuming from the same topic.
So what do partitions and consumer groups give us? Partioning allows us to scale out and limiting consumption of a partition to a single consumer maintains strict ordering when processing the messages. Also consumers can leverage batching (for higher scalability) without affecting the even distribution of messages across consumers.
When we have two or more partitions we don't get global ordering over a topic. But we can use hashing based routing to ensure that messages of the same Record Id always go to the same partition. This gives us the necessary ordering guarantees as the messages of customer X always go to the same partition.
Also the ordered messages of a given partition can only be consumed by one consumer (of the same consumer group), which means we maintain ordering of processing as well. This means that we get strong ordering guarantees that we need while also scaling out.
Compare that to RabbitMQ. We can have multiple consumers consuming from a single queue, there is no restriction on the number of consumers of a given queue. But the result is that while the queue is ordered, processing is parallelised and so ordering is weakened. We also are limited to the scalability of a single queue (which for most usecases is easily enough).
Fig 7. Competing consumers of a single queue. Message ordering weakened, limited to scalability of a single queue.
But we can achieve the same scaling out and ordering guarantees via the Consistent Hash Exchange. We can create multiple queues and configure the exchange to route based on a hash of the routing key. Structurally we now have the same units of topic and partitions that we get with Kafka. We just need to ensure that we only have a single consumer per queue, this is not something that RabbitMQ prevents us from doing.
This is where Kafka has the big edge as it can perform automatic assignment of partitions to consumers, ensuring only one partition is consumed by one consumer per consumer group. This becomes very important in large dynamic environments where we might have hundreds of partitions and consumers might come and go. It also means that adding partitions does not involve complex configurations and deployments. Whenever a change in the partitions or consumers occurs a rebalancing is triggered where all consumers stop consuming and Kafka reassigns the partitions.
This rebalancing is not offered by RabbitMQ. In this post we'll look at using a library called Rebalanser to wrap our RabbitMQ library usage to achieve RabbitMQ consumer groups - automatic queue assignment and rebalancing within a group.
RabbitMQ Consumer Groups - Rebalanser
I developed Rebalanser specifically for this use case, but it is pretty generic and uses the terms Resource Group instead of Consumer Group as it can perform automatic assignment of any resource among any group of nodes.
Note: Currently Rebalanser is only available as a .NET Standard 2.0 library at version 0.1, using SQL Server as a backend. The plan is to add more backends such as Consul and more languages: Python, Java, Go etc. The idea is to be able to use your existing data store as a backend so that you don't need to deploy new server software that you need to run and maintain.
With Rebalanser each consumer application wraps its RabbitMQ code with a RebalanserContext. Each application acts as a node, being the Coordinator or one of many Followers.
The context manages the coordination between consumers to elect a Coordinator node which monitors the Follower nodes, detects when it needs to trigger rebalancing and coordinates the rebalancing behaviour.
Fig 8. Rebalanser manages queue assignment and rebalancing, using SQL Server as a backend.
A relational database with ACID guarantees and serializable transactions makes for an easily available and reliable distributed locking backend. Rebalanser uses this to perform leader election (of the Coordinator) and also as a communication medium for the Coordinator to:
monitor the liveliness of Followers (detecting when a Follower dies for example)
instruct Followers to stop consumption
assign queues Followers and instruct them to consume again
In the future I'll be adding PostgreSql and Consul as backends.
The RebalanserContext offers three events that can be handled:
OnAssignment
OnCancelAssignment
OnError
The recommended way of integrating with Rebalanser is to create a Task (TPL) which contains its own RabbitMQ channel and optionally its own connection for each assigned queue. Ensure that the Task is cancellable via a CancellationToken. When OnAssignment fires, you set up your consumer tasks.
When rebalancing is triggered, the OnCancelAssignment event handler is called first and you can cancel your active consumer tasks. Next OnAssignment is fired and you set up your consumer tasks again with a new set of queues.
The below example console application is a member of the "NotificationsGroup" resource group (aka consumer group). It starts a RebalanserContext and in the OnAssignment event handler it starts an EventingBasicConsumer in a separate Task for each assigned queue.
The OnCancelAssignment event handler fires when rebalancing is triggered and calls Cancel() on the CancellationTokenSource of each consumer task.
using RabbitMQ.Client;
using RabbitMQ.Client.Events;
using Rebalanser.Core;
using Rebalanser.SqlServer;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
namespace ExampleConsoleApp
{
public class ClientTask
{
public CancellationTokenSource Cts { get; set; }
public Task Client { get; set; }
}
class Program
{
private static List<ClientTask> clientTasks;
static void Main(string[] args)
{
Providers.Register(new SqlServerProvider("Server=(local);Database=MyNotificationsApp;Trusted_Connection=true;"));
RunAsync().Wait();
}
private static async Task RunAsync()
{
clientTasks = new List<ClientTask>();
using (var context = new RebalanserContext())
{
context.OnAssignment += (sender, args) =>
{
var queues = context.GetAssignedResources();
foreach (var queue in queues)
StartConsumingQueue(queue);
};
context.OnCancelAssignment += (sender, args) =>
{
LogInfo("Consumer subscription cancelled");
StopAllConsumption();
};
context.OnError += (sender, args) =>
LogInfo($"Error: {args.Message}, automatic recovery set to: {args.AutoRecoveryEnabled}, Exception: {args.Exception.Message}");
await context.StartAsync("NotificationsGroup", new ContextOptions() { AutoRecoveryOnError = true, RestartDelay = TimeSpan.FromSeconds(30) });
Console.WriteLine("Press enter to shutdown");
while (!Console.KeyAvailable)
await Task.Delay(100);
StopAllConsumption();
Task.WaitAll(clientTasks.Select(x => x.Client).ToArray());
}
}
private static void StartConsumingQueue(string queueName)
{
LogInfo("Subscription started for queue: " + queueName);
var cts = new CancellationTokenSource();
var task = Task.Factory.StartNew(() =>
{
try
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using (var connection = factory.CreateConnection())
using (var channel = connection.CreateModel())
{
channel.basicQos(1); // one message at a time
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body;
var message = Encoding.UTF8.GetString(body);
LogInfo($"{queueName} Received {message}");
// start work here -------
// ...
// ...
// end of work -------
// acknowledge message (you'll need error handling also)
channel.BasicAck(ea.DeliveryTag, false);
};
channel.BasicConsume(queue: queueName,
autoAck: false,
consumer: consumer);
while (!cts.Token.IsCancellationRequested)
Thread.Sleep(100);
}
}
catch (Exception ex)
{
LogError(ex.ToString());
}
if (cts.Token.IsCancellationRequested)
LogInfo("Cancellation signal received for " + queueName);
else
LogInfo("Consumer stopped for " + queueName);
}, TaskCreationOptions.LongRunning);
clientTasks.Add(new ClientTask() { Cts = cts, Client = task });
}
private static void StopAllConsumption()
{
foreach (var ct in clientTasks)
ct.Cts.Cancel();
}
private static void LogInfo(string text)
{
Console.WriteLine($"{DateTime.Now.ToString("hh:mm:ss,fff")}: INFO : {text}");
}
private static void LogError(string text)
{
Console.WriteLine($"{DateTime.Now.ToString("hh:mm:ss,fff")}: ERROR : {text}");
}
}
}
Leader Election
When a node starts up it attempts to acquire a coordinator lease. If the lease is assigned to a different node and still valid, then the node becomes a Follower. If there is no active lease, or if the current lease has expired, then the node is granted the lease and becomes the Coordinator.
Coordinators periodically renew their lease (HeartbeatSeconds property). Followers, on the same cadence, attempt to acquire that lease. This means that when a Coordinator node dies, a Follower will take over once the lease has expired (the expiry period is set by the LeaseExpirySeconds property).
In addition to attempting to acquire/renew leases, all nodes send keep alives on the HeartbeatSeconds period. Nodes are assumed dead if the last keep alive exceeds the lease expiry period. The death of a Follower node will trigger a rebalancing. The death of a Coordinator will trigger a Follower to take over as Coordinator and trigger rebalancing.
Backends
I will be writing more backends so that you can use existing infrastructure. Currently only SQL Server is ready.
SQL Server
The SQL Server backend requires three tables: ResourceGroups, Resources and Clients.
To create a consumer group add a record to the ResourceGroups table:
INSERT INTO [RBR].[ResourceGroups]([ResourceGroup],[LeaseExpirySeconds], [HeartbeatSeconds])
VALUES('NotificationsGroup',60, 25)
Also, for each queue that your Consistent Hash Exchange has a binding to, add a record in the Resources table:
INSERT INTO [RBR].[Resources]([ResourceGroup],[ResourceName])
VALUES
('NotificationsGroup','Notifications.1'),
('NotificationsGroup','Notifications.2'),
('NotificationsGroup','Notifications.3')
You can use the Rebalanser.RabbitMQTools utility to create queues. It will create the Consistent Hash Exchange, the queues and the necessary records in SQL Server. The create command is idempotent and will ensure that at the end the required artefacts have been created.
dotnet Rebalanser.RabbitMQTools.dll Command=create^
Backend=mssql^
ConsumerGroup=NotificationsGroup^
ExchangeName=Notifications^
QueuePrefix=Notifications^
QueueCount=15^
LeaseExpirySeconds=60^
Heartbeateconds=25^
ConnString="Server=(local);Database=MyNotificationsApp;Trusted_Connection = true;"
The tool will create queues with names: Notifications_0001 through Notifications_0015.
Check Out the Github repo
Rebalanser is on Github and nuget.org. For an example application check out the example console app. You will find the database script to create your tables here. You can create a dedicated database or locate the tables in your application database.
Rebalanser has not seen production usage yet, and I cannot guarantee that it handles all failure modes correctly. So feel free to check it out, kick the tyres and open any issues on the repo if you find them. Contributors of other backends are welcome. If you need RabbitMQ consumer group functionality and you use a different language or data store, then message me and I'll see if we can create a Rebalanser that fits your needs.
In the next part we'll deploy a multi-node RabbitMQ cluster, create different sized consumer groups from tens to thousands and see how Rebalanser handles it. It is the holiday season so don't expect the next part for a few weeks.
UPDATE
I have since moved the project here. I am working on getting the SQL Server and an Apache ZooKeeper version to a v1.0 quality status. You can track progress here: https://github.com/Rebalanser/wiki/wiki