
Banner credit: ESO/C. Malin (christophmalin.com)
With the announcement of KIP-932, Queues for Kafka, I thought it was worthwhile a revisit of the subject of queues vs logs and how we actually can build better queues on top of logs.
It’s logs all the way down
“A log is perhaps the simplest possible storage abstraction. It is an append-only, totally-ordered sequence of records ordered by time”. Jay Kreps.
The world is built on logs:
Relational databases write to the journal/write-ahead log (WAL) first for atomicity and durability, then perform mutations on the tables. If a database never trimmed its WAL, you could reconstitute all the tables in the database, just from the log of changes that have been committed to the WAL.
Filesystems. XFS first writes file metadata changes to a log before writing to the file locations themselves.
Distributed data systems and consensus services are often based on State Machine Replication algorithms (such as Raft, ZAB, Paxos etc) where each deterministic state machine instance applies the state machine logic on the same sequence of commands in the same order (via a replicated log).
But queues are also useful data structures and they are also temporally ordered sequences, so what’s the difference?
We’ll get into the differences next but the difference I like to start with is the following:
Consumers of queues just ask for the next item, it is the responsibility of the queue to know which item that is. Because consumers simply ask for the next item, we can spread out load across multiple consumers. Each consumer reads from the queue when it is ready without having to know any details of the internal structure.
Consumers of logs read items by position (or index) in the log. It is the responsibility of the log consumers to know which item they should read next. For this reason, the log doesn’t lend itself to spreading out load over multiple consumers as this would require coordination between those consumers.
Logs tend to be the best choice when you need individual readers to read every log item, in order. A classic use-case for this is data consistency by forcing a total order of operations where the reader doesn’t end up skipping any items.
Queues tend to be the best choice when you want to allow any number of consumers to share the load. Queue consumers are known as competing consumers because each individual consumer may only read a subset of the queue items. With the queue, load distribution is often the primary reason for choosing it, rather than strict ordering or forcing one reader to read all entries. Work queues which spread out load across a pool of workers is a classic example.
I used the word “tend” because there is a large zone in the middle between strong data consistency and large fanout work queues where both can work well. A lot depends on whether low-level or high-level client libraries are used and on the specifics of the use case.
Next we’ll cover the queue and log basics, then move onto queues and logs over network connections and finally cover why queues implemented on top of logs can make better queues.
Queue and log basics
The queue
The queue is a First-In-First-Out data structure where reads are destructive.
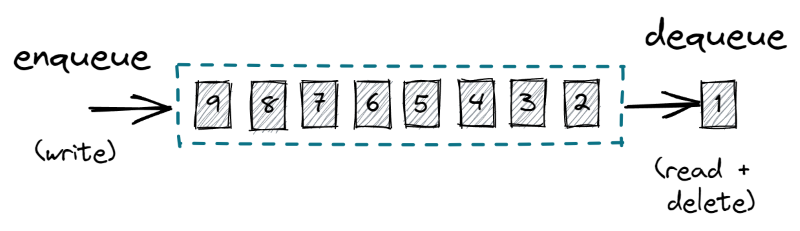
Fig 1. Queue operations
Having destructive reads is a fundamental property of the queue which determines how we use queues, its strengths and weaknesses.
Destructive reads allow the queue to serve multiple consumers in parallel without forcing the consumer to know anything about the internal structure of the queue, such as item position.
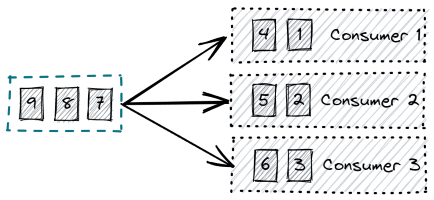
Fig 2. Consumers compete to read items
Because the queue can be consumed in parallel and each read deletes the item, no item is consumed twice by different consumers. We have scaled out our consumption by spreading the processing load over multiple consumers.
But we have given something up with this parallelism — our ordering.
Fig 3. Simple load distribution over multiple consumers loses processing order guarantees.
The queue stores the elements in temporal order and the elements are read in temporal order, but our processing order is not guaranteed when parallelism is used.
The Log
The log may seem very similar to the queue but it is fundamentally different. It is temporally ordered like the queue but FIFO doesn’t apply to the log. Reads from a log are not destructive — you could read the same element again and again forever if you wanted. Instead of reading from the head or tail of the log, the reader maintains a pointer into the log which it advances as it reads. I’ll refer to this pointer as a cursor as it is a pointer that advances along the log.

Fig 4. Log operations
Physically, the log can be an ever growing series of items which must eventually be garbage collected.
Fig 5. Log growth is controlled by garbage collecting the log tail.
Like the queue, the log can support multiple readers — but unlike the queue, log readers each read every item.
Fig 6. Multiple independent consumers. Each consumer consumes every item.
This means the log doesn’t support parallel consumption. If we want to increase the processing speed of consumption, adding another consumer doesn’t help as that consumer will read all the elements independently of the other consumer.
Supporting multiple logical consumers
I define a logical consumer as a set of physical consumers that act together to consume and process a sequence of items. While the physical consumers compete with each other to consume items, as a group they collectively process every single item. A logical consumer could be a scaled out service consuming events, or a multi-threaded process which makes use of parallel processing.
How then do queues and logs support multiple logical consumers?
Fig 7. A single queue cannot support multiple logical consumers
A single queue cannot support multiple logical consumers as these two logical consumers would compete for the items of the queue. Each would only process a subset of the queue items which is not what we want. To support multiple logical consumers, we need to write to two queues, where each logical consumer has a dedicated queue.
Fig 8. Two queues for two logical consumers
We solved the problem by giving each logical consumer its own queue. But now we have write-amplification proportional to the number of logical consumers.
The log doesn’t have this issue as reads are not destructive and therefore a single log can support multiple logical consumers.
Fig 9. One log supports multiple logical consumers.
With the log, we only have to maintain a single data structure no matter how many logical consumers there are. But we have the problem that each logical consumer is limited to a single physical consumer. How to scale out consumption?
This problem is solved by partitioning the log into multiple logs.
Fig 10. Partitioned logs allow for parallel consumption by a single logical consumer.
Producers can choose the partition for each item based on a partition strategy, such as random, round-robin, hashing or some custom strategy.
Bringing this back to the word of real systems, these logical consumers are known as consumer groups (Kafka, Redis), share groups (Kafka KIP-932) or subscriptions (Apache Pulsar, Google PubSub). I’ll use the term subscription from now on.
Durable queues and logs over a network
So far we’ve been focusing on the data structure without considering durability or how reads and writes might occur when the queue/log and consumer are on different machines with a network between them.
The atomic read-delete operations of a durable queue are obviously dangerous when a network is placed in the middle. If a consumer performs a destructive read but fails before being able to process the message then that message is lost — this is at-most-once processing.
If we want at-least-once processing guarantees then we need to separate the read and delete into separate operations. This also means that the queue now needs to maintain a little state machine for each message. We usually use the word “acknowledge” instead of delete, but some queues (SQS) use the delete term.
Fig 11. Each message has a state machine.
What happens to a message that timed out while out for delivery? It gets delivered again. How can we guarantee that we only deliver the message again if the message was definitely not processed? We can’t. The consumer might have processed the message but failed before it could send the acknowledge/delete command. Second question: if we are redelivering messages, can that affect ordering guarantees? Yes it can.
Fig 12. A queue with different messages in different states. Next message 3 will be processed after message 4.
The log also supports at-most-once and at-least-once processing. At-most-once is simply an auto-advancing cursor that is maintained by the log system. Each read by a subscription advances the cursor, whether the message is processed or not.
To make a networked log at-least-once capable we must separate read and cursor advancement (acknowledge) operations.
Fig 13. Reads and cursor advancement split into separate operations to achieve at-least-once.
The read position is committed (as the durable cursor) at some cadence. Once an item has been read and processed, that read position can be committed ( advancing the durable cursor). If the consumer were to fail, another consumer can resume from the where the durable cursor points to.
We can perform multiple reads before advancing the cursor. This makes logs very efficient as the housekeeping of managing message state of a subscription is a single integer number that can be incremented or increased by arbitrary amounts (cumulative acknowledgement). The queue on the other hand has to maintain separate state for each message and some queue systems don’t offer cumulative acknowledgement, i.e. each message or message batch must be acknowledged separately. This makes the queue more computationally expensive than the log.
Replay
A common requirement for a messaging or event streaming system is being able to turn back the clock and re-consume messages from an earlier time period. One example is a bug in an application is detected and fixed, and the organization wants to reprocess messages that were processed incorrectly the first time. Another example is Apache Flink that needs the ability to go back to a previous read position when restoring a cluster from a snapshot.
Queues by themselves cannot allow consumers to go back and re-consume messages that were previously consumed. Logs on the other hand offer this feature as a subscription only need move its cursor backwards to an earlier message.
Queue vs log summary so far
Queues:
Destructive reads
No message replay
Parallel consumption
One queue per subscription
Per-message state
Logs:
Non-destructive reads
Message replay
Serial consumption (parallel consumption via partitioning)
One log, multiple subscriptions
Single cursor per subscription
Queues implemented on logs
It’s logs all the way down — we can pretty much represent anything on top of a log - including queues. When it comes to queues vs logs, it’s all about the consumption model.
Queue semantics for consumers
As we already covered earlier, a queue must represent the delivery state of each message. This state is metadata, not the actual message data itself. We can maintain this message metadata separately from the actual messages themselves by storing the messages in a log, and the metadata in a map.
Fig 14. A queue can just be metadata that points into a log.
With queues, each subscription needs its own queue. With queue semantics, each queue is simply a metadata map that is updated as messages are written to the log and consumed by the subscription.
Fig 15. Multiple queues over the same log.
Multiple subscriptions means multiple separate metadata maps, independently maintained. This gives us virtual queues over a single shared log. We just solved the write-amplification problem of the pure queue data structure.
We’ve also solved another limitation of queues — replay. Because a queue is simply metadata, we can rewind the queue head backwards to an earlier point. Suddenly the queue vs log debate gets more nuanced. Queues with log capabilities blur the lines.
Producers don’t know or care about any of this. Producers write messages to the log as always. In theory, the consumer can choose whether it wants log semantics or queue semantics.

Fig 16. Producers append, consumers can choose log or queue semantics.
Queue semantics can also work over partitioned logs where each partition maintains its own metadata map. How load is distributed across consumers and partitions depends on the design. One possibility is for all consumers of a subscription to register with every partition of a topic and each partition independently dispatches messages across this pool of consumers. Kafka share groups have a design similar to the current consumer groups where consumers are balanced over partitions by a share coordinator.
Queue Semantics and Ordering
Earlier I described that you can’t always get ordered message processing with a queue due to parallel consumption and message redelivery. But both these issues are solvable.
Partitioned logs can offer partial ordering, by message key, by ensuring that all messages of the same key always get written to the same partition and then only allowing a single consumer per partition. Partitioned logs actually store data in a partial order but queues can offer a partial order but by performing key-aware message dispatching.
The problem of ordered processing and queues is that the classic way queues dispatch messages is simply on-demand. But if the queue were to dispatch messages of the same key to the same consumer, then we could get a partial order for message processing even though there are multiple consumers in the subscription. This is offered for example by Google PubSub Streaming Pull Requests.
Fig 18. Non-blocking keyed dispatch. Messages of the same key get delivered to the same consumer. Requires a session-based protocol.
Non-blocking keyed dispatch needs to know who the consumers are so it can divide up the key hash space evenly between them. This only works with a session-based protocol that allows the system to know when new consumers appear and existing ones disappear.
A different trick to giving queues partially ordered processing guarantees is a blocking keyed-dispatch. This strategy doesn’t require sessions and supports completely request-based protocols. This strategy blocks delivery of a message while there are outstanding messages of the same key pending acknowledgement. This is how SQS FIFO queues work.
Fig 19. Blocking keyed dispatch. The queue only dispatches messages of a given key if there are no messages of that key outstanding.
Logs maintain message ordering despite message redelivery. If the message at offset X is redelivered because the cursor was not advanced before the prior consumer failed, then all messages X+1, X+2…X+N in that partition are also redelivered in the original temporal order. So while we may jump backwards an arbitrary amount, after that all messages are delivered in order again. This is critically important behavior for log consumers who often require the data consistency that this model provides - such as Apache Flink recovering from a snapshot.
Queues backed by logs can also behave this way. The queue can ensure that if a message is redelivered, then all messages X+1, X+2…X+N of the same key (or keys belonging to the same hash space that a consumer owns) are also redelivered . Google PubSub has similar redelivery behavior.
Conclusions
The lines between queues and logs has blurred over the years. Some queues can do things that logs can do (because they are backed by logs), with Kafka Share Groups (KIP-932) and Pulsar shared/key-shared subscriptions falling in this category. I’ll place Google PubSub here as well though I don’t know that its storage layer is log-based.
Some logs can do things that queues can do given the right client-side framework. Spring for Apache Kafka and Confluent Parallel Consumer are both examples of frameworks or libraries that give traditional queue semantic capabilities to log based systems.
What is clear is that there are clear advantages to offering a queueing API over a shared log. Many of the disadvantages of queues such as write-amplification and lack of replay are solved this way.
If you are interested in learning more about share groups then check out the KIP and also get involved in the mailing lists. This is open-source and you have a voice in its future.