The Redpanda benchmark and TCO analysis claims that Redpanda needs only 3 brokers on the i3en.6xlarge to reach 1 GB/s and Apache Kafka needs 9 brokers and Kafka still shows inferior end-to-end latency to Redpanda. I decided to see if I could reproduce those claims and see if the Redpanda performance was generalizable. That is, does the 1 GB/s with 4 producers and consumers translate to other workloads? I.e, is it a useful benchmark you could make decisions off?
I ran the Redpanda 1 GB/s benchmark against Redpanda and Apache Kafka on identical hardware at 6 different throughputs: 500, 600, 700, 800, 900 and 1000 MB/s. I also ran it with the original 4 producers and consumers, then with 50 producers and consumers. The result was significant performance degradation with 50 producers for Redpanda. The other noteworthy result was that Redpanda was unable to reach 1000 MB/s with TLS which conflicts with the Redpanda benchmarks.
My benchmarks do have slightly higher throughput as I wanted the OMB charts for these 500-1000 MB tests to reach each y-axis hundred tick mark. I will use KB and MB to mean the base 2 version not the base 10, so strictly speaking KiB and MiB. The original benchmarks for example use a message size of 1024 and a producer rate of 1,000,000 which is 1 million KB or 976 MB. To avoid the charts always falling short, the producer rates are configured slightly higher, for example, the 1000 MB/s uses a producer rate of 1,024,000 messages per second.
The benchmark
This 500 MB/s to 1000 MB/s benchmark consists of:
1 topic with 288 partitions
Either:
4 producers and 4 consumers
or 50 producers and 50 consumers
Producer config:
batch.size=131072
linger.ms=1 - the client will delay emitting a batch by up to 1 ms if the batch size has not been reached yet.
Consumer config:
enable.auto.commit=false (do manual offset commits)
offsetCommitLingerMs=5000 (not a Kafka config, but for these drivers - commit offsets every 5 seconds)
max.partition.fetch.bytes=131072
Null record key - which means that the default partitioner sends each batch to a random partition. This should be great for performance because we should be sending big batches. This mode is not a good choice for real-world applications that care about message ordering - but for performance it is the best choice.
Versions:
Kafka clients: 3.2.0
Redpanda: v23.1.7
Apache Kafka: 3.4.0
Kernel: 5.15.0-1026-aws (Ubuntu)
500 MB/s results
Without TLS Redpanda did well with 4 producers, but far worse with 50 producers.
Fig 1. Redpanda end-to-end latency with 50 producers reaches 700 ms, far higher than its results with 4 producers and higher than Kafka.
Running the test with TLS made the Redpanda 50 producer performance degrade further.
Fig 2. With TLS, Redpanda performance with 50 producers degraded significantly, reaching 24 second end-to-end latency.
1000 MB/s results
Fig 3. Without TLS, Redpanda could reach 1 GB/s with 4 and 50 producers, but its end-to-end latency with 50 producers also reached 24 seconds.
We see that Redpanda did really well with 4 producers and consumers but again struggled with 50 producers and consumers. So far, it doesn’t seem like the Redpanda published benchmark results can be translated broadly.
I was unable to get Redpanda to 1000 MB/s with TLS, even with the sweet spot of 4 producers. I ran this three times on separate deployments and the chart above shows the best Redpanda result.
This might be a performance regression or the fact that this test has a target throughput of 1000 MB/s instead of the Redpanda benchmark which sets the target throughput at 976 MB/s.
We see below that Redpanda just falls short of 1000 MB/s with 4 producers and only reaches around 850 MB/s with 50 producers.
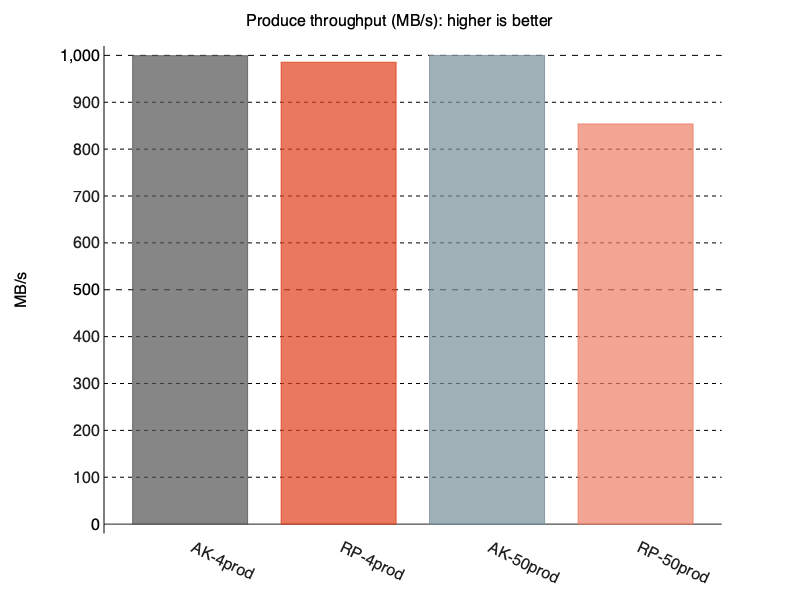
Fig 4. With TLS, Redpanda could only manage 850 MB/s with 50 producers, where as Kafka comfortably managed the target 1000 MB/s.
Conclusions
By simply changing the producer and consumer count from 4 to 50, Redpanda performance drops significantly. Looking at the Redpanda metrics for the non-TLS run we see indications that 50 producers causes a lot more CPU utilization, fsyncs, internal tasks and inter-broker communication. It is plausible to assume this is the cause of the performance degradation with 50 producers with the same aggregate throughput.
Fig 5. Left: 4 producers (500-1000 MB/s steps). Right: 50 producers (500-1000 MB/s steps). Without TLS. With 3x 24 vCPU instances, the maximum CPU time would be 72K ms.
Adding producers changed everything, with CPU utilization going from about 25% at 500 MB/s to 76% at 500 MB/s.
It turns out that you don’t need 9 Apache Kafka brokers to do 1 GB/s on the i3en.6xlarge instance type. It also turns out that Apache Kafka might deliver higher throughput and lower end-to-end latency, even the tail latencies. It all depends on the workload.
While workloads with 250 MB/s per producer exist, they are more niche than lower per producer throughputs. For this specific workload with a single topic, with 288 partitions, Redpanda shows excellent performance with 4 producers. In fact, throughout my benchmarking, 4 producers seems to be the Redpanda sweet spot. Kafka on the hand tends to do better overall with more producers.
Given that Redpanda can only reach 850 MB/s with TLS and 50 producers, it seems that the TCO claim doesn’t add up. This first example shows that using a single synthetic benchmark cannot be used as a guide for all workloads. While Redpanda is capable of excellent performance, by no means are you guaranteed to get it. Always verify for yourself, using a workload that is similar to what you have in production. From my experience that means more topics, more partitions and more producers and consumers.
How to run this test
To run my 500-1000 MB/s tests see my benchmark repository where Kafka is configured correctly and with Java 17. You can run the Redpanda benchmark by simply swapping producersPerTopic: 4 for producersPerTopic: 50 and consumerPerSubscription: 4 for producersPerTopic: 50.
The workload files and instructions are also on my OMB repository here.
Series links:
Kafka vs Redpanda performance - Part 1 - 4 vs 50 producers
Kafka vs Redpanda performance - Part 3 - Hitting the retention limit
Kafka vs Redpanda performance - Part 4 - The impact of record keys
Kafka vs Redpanda performance - Part 5 - Reaching the NVMe drive limit