
Image credit: ESO/A. Ghizzi Panizza (www.albertoghizzipanizza.com)
Two systems I know pretty well, Apache BookKeeper and Apache Kafka, were designed in the era of the spinning disk, the hard-drive or HDD. Hard-drives are good at sequential IO but not so good at random IO because of the relatively high seek times. No wonder then that both Kafka and BookKeeper were designed with sequential IO in mind.
Both Kafka and BookKeeper are distributed log systems and so you’d think that sequential IO would be the default for an append-only log storage system. But sequential and random IO sit on a continuum, with pure sequential on one side and pure random IO on the other. If you have 5000 files which you are appending to in small writes in a round-robin manner, and performing fsyncs, then this is not such a sequential IO access pattern, it sits further to the random IO side. So just by being an append-only log doesn’t mean you get sequential IO out of the gate.
So, in the age of the HDD, system builders designed sequential IO into their systems. Apache BookKeeper goes to the greatest lengths to achieve sequential IO by ensuring there is only one active file at a time. It does this by interleaving data from different logical logs into one physical log. Interleaving like this is fine for writes but reads become a problem as we no longer get sequential reads. To solve this, BookKeeper writes data twice: once to a write-optimized Write-Ahead-Log (WAL) and then again to long-term read-optimized storage. To make the long term storage read optimized, BookKeeper accumulates written entries in a large write cache and then periodically sorts the cache and writes it to one active file (at a time). The sorting by log id and entry id ensures that related data is written in contiguous blocks which then makes reads more sequential. We just need to add an index that can point to these contiguous blocks.
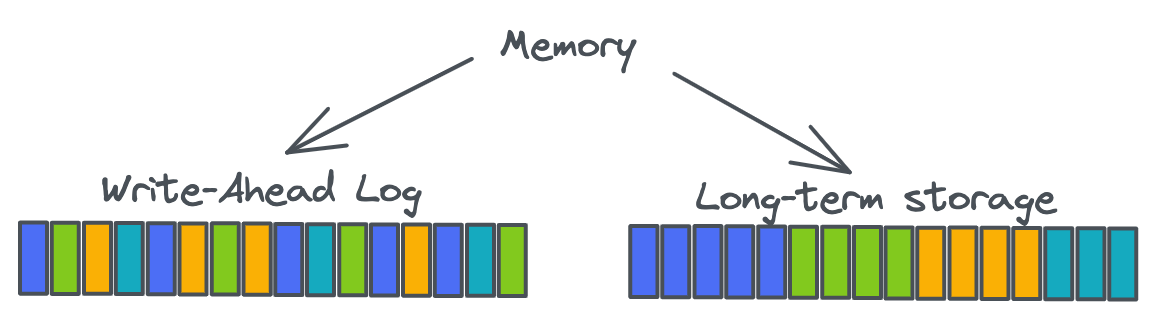
Typically we put the WAL on one disk and the long term storage on another. Writes to the WAL are purely sequential and writes to long-term storage are purely sequential. Reads might have to hit the index occasionally but are typically sequential also. With a single active WAL, BookKeeper can fsync like every 1 ms and it doesn’t get too expensive - we’re just writing to a single file at a time. We can scale out both the WAL and long-term storage by adding more disks and creating more WAL and long-term storage engine instances, each with its own thread pool.
Apache Kafka takes a different approach to realize sequential IO. It maps one partition to one active segment file at a time which sounds bad at first. If a broker hosts 1000 partitions then it will be writing to 1000 files at a time. This can get expensive, especially for HDDs. To solve this Kafka has two import design points. Firstly, it is designed to write to disk asynchronously, it relies on the page cache to flush data to disk, which results in larger (sequential) blocks of data being written to disk. This reduces the cost of writing to so many open files. Finally, writing to disk asynchronously is unsafe unless you also build the replication protocol to handle arbitrary loss of the log head. When you write to disk asynchronously, you might lose some of the most recently written entries if the server were to crash for example. I recently wrote about Kafka’s recovery mechanism built into its replication protocol which allows it to use this asynchronous log writing.
The era of NAND flash
But in today’s world of SSDs is this design ethos now outdated? High performance SSDs can deliver high throughput and low latency on random IO workloads, so does that mean we should leave sequential IO behind? Should we design our distributed log storage systems to make use of random IO and thereby free ourselves of these tricks to achieve sequential IO?
The truth is that SSD drives, including NVMe, are not agnostic to the IO access pattern. Alibaba Cloud wrote two interesting posts about factors affecting NVMe drive performance. One interesting aspect of NVMe drives is the amount of required housekeeping, such as wear leveling and garbage collection.
Wear leveling prevents NAND blocks from being worn out due to too many read and write cycles. It does this by relocating hot data to less worn out blocks. Garbage collection is another housekeeping process where the drive controller is rewriting blocks of data when fragmentation has caused a lack of free blocks.
Inside an NVMe drive, data is written to pages (typically 4 Kb) and pages belong to blocks (typically 128 pages per block).
The drive controller can write directly to empty pages, but it cannot overwrite a page. The controller also cannot erase individual pages, only entire blocks. When a controller wants to overwrite a page, it actually just writes to an available empty page, updates the logical-to-physical mapping table and marks the old page as invalid. These invalid pages build up and cannot be written to so the controller must periodically do housekeeping to deal with the invalid pages - this process is known as garbage collection (GC). Without GC you’d soon run out of space on the drive as all blocks would be full of either valid and invalid pages.
The way GC works is that it reads a block and rewrites all the valid pages to an empty block, updates the mapping table and erases the original block.
This rewriting causes write-amplification because for each page written, there is a certain amount of rewriting. All this backend traffic on the drive reduces the performance and also reduces the lifespan of the drive.
Simply deleting a file doesn’t erase all the pages inside the drive. Instead those pages are marked as invalid and the GC process will eventually free those invalid pages via the process above.
This means that once the entire drive has been written to once, the throughput of the drive is now limited to the throughput of the GC process - the more work GC has to do, the lower the throughput and higher the latencies on disk operations.
This is where the sequential vs random IO question becomes relevant. Sequential IO fills entire blocks whereas random IO tends to scatter writes across blocks, fragmenting any given file across a host of blocks. On an empty drive this difference has no impact as there are plenty of free blocks available. However, once a drive has been under load for days and weeks, this fragmentation has a big impact on GC.
Sequential IO causes a lower GC overhead because it fills entire blocks and then later, when a file is deleted in the filesystem, entire blocks become invalid. The GC process doesn’t have to rewrite pages of a block that is formed only by invalid pages. It simply erases the block. However, with random IO, all the blocks have a mix of valid and invalid data so before a block can be erased for new writes, the existing valid blocks must be rewritten. This is why write-amplification of sequential IO loads is close to 1 but random IO is typically much higher.
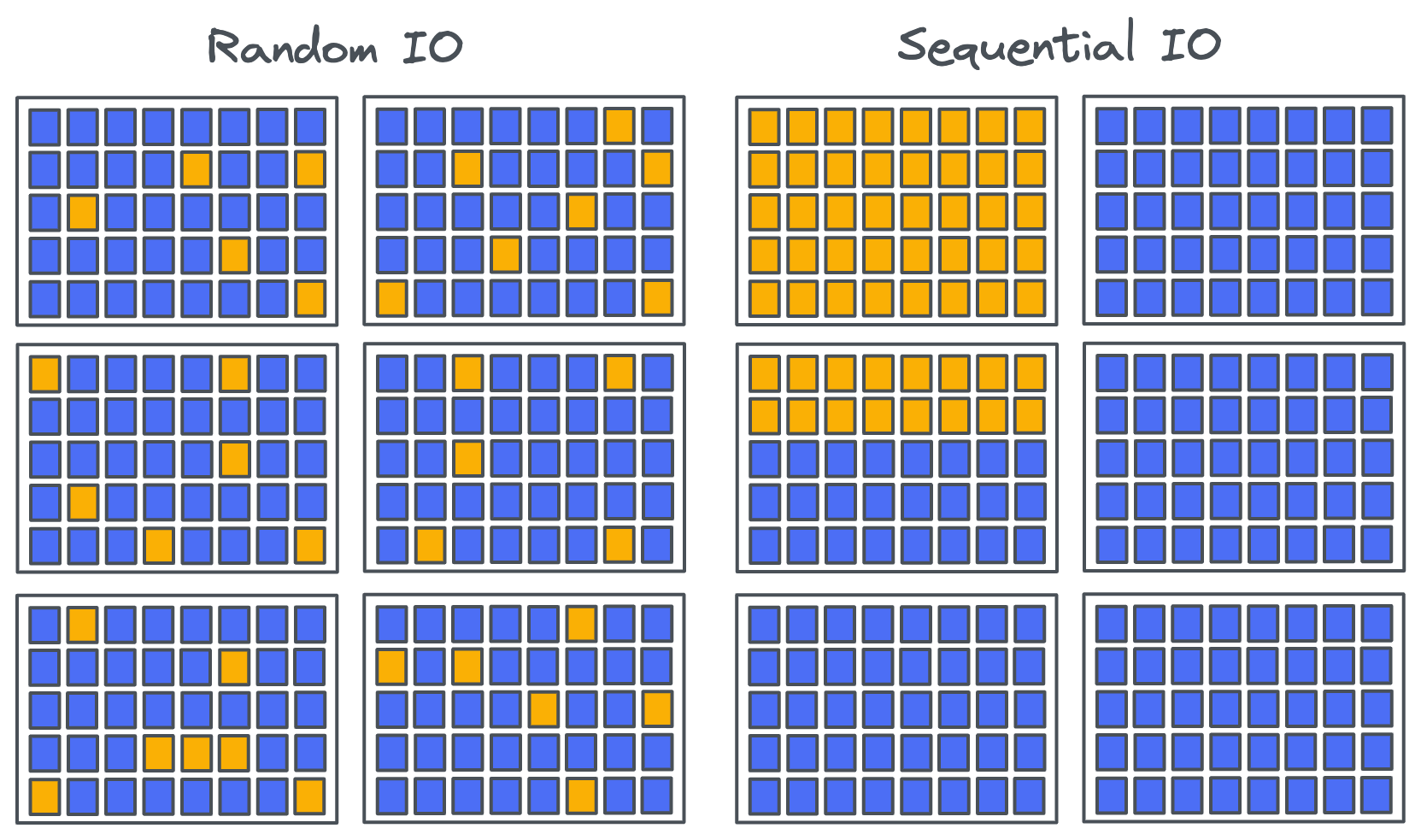
Eventually, your drive will end up with much of its non-reserved blocks containing a mixture of stale and in-use pages. At this point, new writes will likely cause significant write amplification and degraded performance as the controller shuffles in-use pages around into other cleared blocks. A one-page write may end up with many hundreds of other pages shifted around in a cascade of cleaning.
Over-provisioning to the rescue
But it isn’t all bad news for random IO. The cost of GC can be mitigated by providing the drive additional space only reserved for itself which it can use for GC. The less free space a drive has, the higher the write amplification and the larger degradation on performance. Typically once we pass 50% of the drive containing valid data we’ll see some kind of performance impact with random IO which grows larger as we reach 100%.
Over-provisioning (OP) is the concept of reserving space just for the drive controller. For example, with an OP of 7%, the drive controller gets that 7% to itself and the OS cannot write to it. Enterprise-grade SSDs come with a certain percentage of over-provisioning built-in whereas AWS local instance store NVMe drives come with none. There are different techniques for implementing OP yourself. You can simply leave a portion of the drive unpartitioned or use a tool like hdparm.
Further increasing over-provisioned space can reduce the backend traffic of GC, but it comes at the expense of decreased storage density and increased costs. The issue of write amplification and its sensitivity to random IO workloads has long been known to flash memory and drive manufacturers. Still, this limitation often flies beneath the radar, and many people are unaware of it.
A paper from 2010, entitled The Fundamental Limit of Flash Random Write Performance: Understanding, Analysis and Performance Modelling (by X.-Y. Hu, R. Haas) covers the interactions and limitations that average write size, controllers, garbage collection algorithms, and random IO has. They found that with random IO, performance can really start to fall off a cliff once you get to around 2/3rd disk utilization. As their Figure-7 shows, even varying the write payload size has minimal effect on the actual slowdown factor.
NVMe drive technology is still advancing but we still face these fundamental problems of fragmentation and housekeeping. the authors of The Fundamental Limit of Flash Random Write Performance close out their paper with the following observation:
“The poor random write performance of Flash SSDs and their performance slowdown can be caused by either design/implementation artifacts, which can be eliminated as technology matures, or by fundamental limits due to unique Flash characteristics. Identifying and understanding the fundamental limit of Flash SSDs are beneficial not only for building advanced Flash SSDs, but also for integrating Flash memory into the current memory and storage hierarchy in an optimal way”
I find this part of the conclusion important, especially since it was written 13 years ago. Technology has certainly improved since then, with far greater drive densities, better controllers, and better GC algorithms. But even the latest cutting edge NAND drives suffer from the same fundamental problems of page fragmentation and the need for garbage collection.
A more modern paper from 2022, Improving I/O Performance via Address Remapping in NVMe interface, discusses overcoming the Random IO issue via a remapping algorithm that translates random IO to sequential IO, with some promising experimental results.
The above figure shows the throughput of random writes on an 8 core Intel Core i9-9900K, 16GB of memory and Samsung PM1725b NVMe SSD.
This paper also has an extensive “related works” section with links to many other interesting studies on NVMe drive performance optimization.
Coming back to the original question
So I come back to the question of whether sequential IO is dead in the era of the NVMe drive, and the second question of whether Apache Kafka and Apache BookKeeper, designed for sequential IO, are now outdated. It seems to me that the benefits of sequential IO are alive and well, even in this new era of NAND flash. Sequential IO has more mechanical sympathy for all drive types and for SSDs in particular, reduces write-amplification which in turn increases performance, allows you to use more of your drive as over-provisioning is less important and extends drive lifespan.
There is a lot more to SSD drive performance than I have mentioned in this post. Below are some links to interesting articles that discuss SSD performance.
Further reading:
Alibaba Cloud - Factors affecting SSD NVMe drive performance (part 1)
Alibaba Cloud - Factors affecting SSD NVMe drive performance (part 2)
Paper: Improving I/O Performance via Address Remapping in NVMe interface
Paper: The Fundamental Limit of Flash Random Write Performance
Samsung PDF on Over-Provisioning
A question on Server Fault
Wayback machine link to a Seagate blog post “Lies, damn lies and SSD benchmarks”.
Richard Durso writes about Over-Provisioning SSD for Increased Performance and Write Endurance