
Invariants get most of the attention because they are easy to write, easy to check and find those histories which lead to really bad outcomes, such as lost data. But liveness properties are really important too and after a years of writing TLA+ specifications, I couldn’t imagine having confidence in a specification without one. This post and the next is a random walk through the world of model checking liveness properties in TLA+.
The outline is like this:
Part 1: I (hopefully) convince you that liveness properties are important. Then implement a gossip algorithm in TLA+ and use liveness properties to find problems.
Part 2: Continue evolving the algorithm, finding more and more liveness problems, overcome some challenges such as infinite state-space and impart some helpful principles - making you a better engineer and thinker by the end.
Note! If you don’t know much about TLA+ then I recommend reading my primer on TLA+ first as this post assumes some pre-existing knowledge of TLA+ basics.
Liveness properties, a surprisingly useful (and necessary) tool
I’ve been writing TLA+ for a number of years now and for me TLA+ is an engineering tool. I don’t have particularly impressive skills with Math but I am good at thinking in systems and algorithms. Formal modelling has taught me a number of things about system design such as thinking about system design from the perspective of desired properties and principles.
Properties are verifiable; a system can be proven to satisfy a property mathematically or not. This gives us an extremely powerful tool as we can take a high level design and actually prove whether it satisfies important properties that we care about. With formal verification, properties generally fall under either safety or liveness.
Safety properties assert that bad things don’t happen. A safety property can be checked at any moment and the property is either holding or is violated. Usually, a safety property takes the form of an invariant. For example, an invariant may state that an acknowledged record exists on at least one server at all times. We can check the modeled system continuously and the moment an acknowledged write does not exist on any server, that property is violated. These are typically the easiest type of property to reason about and check.
Liveness properties assert that something good eventually happens. It’s no good that your replication protocol doesn’t lose data when it is unable to commit any data because it gets stuck. Liveness properties cannot be checked at any moment in time as individual states cannot violate this type of property. Instead entire histories must be checked to see if they violated the liveness property by not eventually reaching a valid state that the property says should be reachable. Liveness properties are generally harder to specify and reason about.
An example of a liveness property could be that once a traffic light is red, it will eventually become green. If faulty logic could cause the traffic light to become stuck in red forever, that property would be violated. Liveness property violation examples include basic logic bugs but also getting stuck due to things like deadlocks, messages which get ignored forever causing infinite retries and cycles which can cause livelock.
It is common for beginners to skip liveness entirely and concentrate on the safety properties and that is what I myself did. But over the years I have come to rely heavily on liveness properties for a couple of reasons:
Liveness properties are excellent at finding bugs in specifications. Writing specifications is challenging (but fun!) and it is part of the normal course of developing a spec to have difficult to find bugs which lead to certain expected states never being reached. If a specification has a liveness bug then it could very well be hiding a design flaw because a large amount of the valid state-space remains unexplored. This is the kind of silent killer that puts fear into all specification writers. Did it find no counterexamples because it is perfect or because of a bug in my spec?
Liveness properties are excellent at finding flaws in designs and shortcomings in thinking, especially early on in the design process. It is all too easy to not see all the ways that the system can become blocked or not reach a state that I know should be possible. Often there is an unexpected interaction or an overly conservative enabling condition that causes the good outcome to never be reached.
Liveness properties are important but over the years I’ve encountered some challenges implementing them which ultimately has led to some general principles I like to follow when writing specifications. This post and part 2 will use a simple, contrived case study to demonstrate how to apply liveness properties and some general principles I use.
Liveness case study - a simple gossip algorithm
There are many gossip algorithms, including epidemic or infection-style algorithms. In this contrived example we’ll use a laughably simplistic gossip algorithm as the aim is to learn about checking liveness properties, not the state of the art of gossip/epidemic algorithms.
We’ll name the algorithm Gossa (GOSSipAlgorithm) which is a word for dog in Catalan (I live in Catalonia, Spain).
Gossa is an algorithm for nodes in a cluster to share information about which nodes are alive and dead in a static group. Each node periodically exchanges it’s entire knowledge with a random peer… that’s it.
An exchange goes like this:
Node 1 sends a gossip message to a peer, Node 2. The message includes a map of node id -> known state (Alive or Dead) for every node in the group.
Node 2 receives the message and merges that knowledge with its own. In terms of precedence, Node 2 trusts its own state of Alive or Dead but blindly accepts the Alive/Dead value for all other members in the received map.
Node 2 then replies to Node 1 and includes its entire, updated knowledge in the reply.
Node 1 receives the reply and merges the map with its own (trusting its own state, but blindly overwriting all over Alive/Dead values for the other nodes).
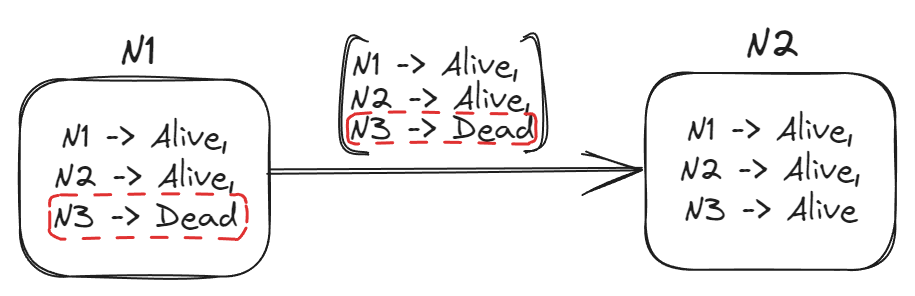
Fig 1. Node 1 gossips its knowledge of the group to node 2
On top of that, nodes can:
Die
Start
Correctly or incorrectly detect that a peer has died and update its state for that peer to Dead.
It’s a pretty terrible algorithm. Let’s go and implement it in TLA+.
Gossa (v1)
We only need one constant and two variables:
Nodes is a set of nodes numbered 1 to NodeCount. If we set NodeCount = 3 then Nodes will be the set {1, 2, 3}. The variables are maps whose key is the node id and value depends on what we want to store. The values in the running variable are boolean values which indicate if the node is running or not. The values in peer_status is a map of node id to status (Alive/Dead).
We initialize the group with all nodes running and all nodes knowing that every other node is alive.
For a three node group, the initial state would be:
----------------------------------------------------
running = [1 = TRUE,
2 = TRUE,
3 = TRUE]
peer_state == [1 = [1 = Alive, 2 = Alive, 3 = Alive],
2 = [1 = Alive, 2 = Alive, 3 = Alive],
3 = [1 = Alive, 2 = Alive, 3 = Alive]]
-----------------------------------------------------The above is a pseudocode representation. In our TLA+ spec we represent Alive as the number 1 and Dead as the number 2. In TLA+ syntax the initial state would be represented as:
running = <<TRUE, TRUE, TRUE>>
peer_state = << <<1, 1, 1 >>,
<<1, 1, 1 >>,
<<1, 1, 1 >> >>Next we define the actions that can happen in Gossa.
The below action specifies what happens when a node dies. It describes that there exists a node in the set of nodes, such that it is running and then it dies. In the next state, it sets the running value for only that node to FALSE. It leaves the peer_status variable unchanged.
\E is the there exists an x such that syntax which represents the non-deterministic selection of a node (known as the existential quantifier). The /\ symbol means AND. There is only one enabling condition for this action: that the node be running.
Start is defined as the opposite of Die.
There is only one enabling condition for this action: that the node be not running.
Correctly detecting a dead node requires at least one node to be alive (so it can do the detection) and at least one node to be dead, and additionally, the alive node should start off thinking that the other node is alive, so it can detect its death and update its status locally.
We have four enabling conditions above:
The local and remote nodes that are non-deterministically selected must not be the same node.
The local node must be running.
The remote node must be not running.
The local node must think the remote node is alive.
Then it updates its peer_status map in the next state, setting the value of the remote node to dead.
The FalselyDetectDeadNode action does the same as above but changes the enabling condition running[remote] = FALSE to running[remote] = TRUE.
If the first action to happen after the initial state were for a node to falsely detect the death of a peer we might see the following state:
running = <<TRUE, TRUE, TRUE>>
peer_state = << <<1, 1, 2 >>,
<<1, 1, 1 >>,
<<1, 1, 1 >> >>The above state tells us that Node 1 incorrectly believes that Node 3 is dead.
Finally we need to specify the gossip exchange action. I model this as an atomic exchange of knowledge, rather than an explicit message passing sequence (to keep this simple).
First let’s define how a node merges gossip with its own knowledge. In this bad algorithm, it will blindly accept whatever the gossip says about other nodes, but trusts its own knowledge about itself.
The above formula builds a new map whose keys are the Nodes and sets the value for each node by either reading from its local knowledge or the remote nodes knowledge.
The enabling conditions for a gossip exchange are:
The gossip source is running.
The gossip destination is running.
The source and destination do not have matching knowledge. This condition is added to prevent an infinite cycle of gossip exchange between two nodes who believe the same thing.
We finish off the actions by defining the Next state formula which you can think of as the static void main. The \/ symbol below means OR, so the Next formula says Gossip or Die or Start or CorrectlyDetectDeadNode or FalselyDetectDeadNode will occur next.
We can get the model checker to run this now though we don’t have any properties yet. The first thing we should add is a TypeOK invariant which ensures that the variables contain valid values.
An example history with 3 nodes might be:
Initial state
Die (node 2)
CorrectlyDetectDeadNode (node 1 detects node 2 is dead)
Gossip (node 1 gossips with node 3 and both now know that node 1 is dead).
I ran the TLC model checker with 16 workers with the NodeCount constant set at different values and ensured that TypeOK was not violated by any bug:
NodeCount=2, unique states found = 16, running time = 4 seconds.
NodeCount=3, unique states found = 512, running time = 4 seconds.
NodeCount=4, unique states found = 65536, running time = 8 seconds.
NodeCount=5, unique states found = 33554432, running time = 4 minutes.
As always, the bigger the model, the bigger the state space. 6 nodes would likely take a few hours. However, this is the first time I’ve seen the unique states increase in multiples of powers of 2.
Adding a liveness property
So far so good, it’s time to add a liveness property. With gossip protocols we care a lot about convergence. Eventually, all nodes should converge on the same knowledge (given that perturbations eventually settle down). We’ll express convergence with a negative: there does not exist a running node that believes a dead node is alive or an alive node is dead.
The /\ symbol means AND, the \/ symbol means OR.
Next we need to specify that eventually this convergence is reached. One way of doing that is to say a diverged system leads to a converged system.
EventuallyConverges ==
~Converged ~> ConvergedThe ~ symbol means “not“ and the ~> symbol means “leads to”. If there exists a history where a diverged system cannot converge then that will violate our EventuallyConverges liveness property.
But we’re not quite done yet, we need to specify which actions must always eventually occur if they are perpetually enabled. Just because an action is enabled (by its enabling conditions being true), it doesn’t mean it will happen. We are modelling non-determinism and in a non-deterministic world, just because something CAN happen doesn’t mean it WILL happen.
We can tell the model checker to eventually execute an enabled action via Strong or Weak Fairness. In our case, we need Weak Fairness. This type of fairness can be used express that if an action becomes enabled and remains enabled ever after then eventually it must be executed. There are two actions that want this for:
Gossip (if two nodes can exchange gossip then they must eventually do that).
CorrectlyDetectDeadNode (if a node has not yet detected a peer is dead, and that peer never starts-up again, then the node must eventually detect it has died).
We can write that as the following formula:
We can run TLC again but tell it to use this liveness formula and check all histories against the EventuallyConverges liveness property.
Gossa v1 liveness checking results
TLC doesn’t find any issues for 2 node clusters, but for 3 node clusters and above it finds various liveness issues. Can you guess what they are?
The problem is that nodes can enter cycles where they contest whether a third peer is alive or dead.
Example of a 4 node cluster cycle:
Node 2 falsely detects Node 1 is dead.
Node 2 then tells Node 3 that Node 1 is dead.
Node 4 then tells Node 2 that Node 1 is alive.
Node 3 then tells Node 2 that Node 1 is dead.
Back to step 3.
Our liveness property has found a problem with our design.
Gossa v2 - fixing the cycles
One established technique to solve this issue of nodes arguing with each other over the alive or deadness of peers is to add precedence to information.
If we make Dead take precedence over Alive, then we should be able to prevent this cycle. We already set Alive to be the integer 1 and Dead to be the integer 2 so now when merging knowledge about a particular peer, we take the highest value.
The local node trusts its own knowledge about itself as before but when evaluating the status of a peer node, it takes the highest value between what it already knows and the gossiped value. If we comment out all actions in the Next state formula except for Gossip and FalselyDetectDeadNode we can specifically check if this cycle is fixed.
Let’s see if that has fixed our cycles…
It did but the cluster is still unable to converge. Can you guess why?
TLC identified no cycles which is great. The flip-flopping between alive and dead has been fixed, the new issue is that once a node is believed dead, no-one pays attention to that node when it exchanges gossip, stating that its own status is alive. When a node knows it’s alive but everyone else thinks it’s dead then no-one will listen to the falsely accused dead node.
The below is an example with a 5 node cluster and TLC detecting the violation of EventuallyConverges.
In fact, false positives spread inexorably because deadness has precedence over aliveness. We need to fix this. There is another established method of handling this issue: allow the falsely accused to refute its deadness via the use a monotonic counter.
We’ll apply this fix in part 2 and confront the new challenges of state-space explosion that emerge from this design change, as well as discuss those general principles I spoke about.
Read Part 2.