
This is a blog series where I share my approach and experience of building a distributed resource allocation library. As far as distributed systems go, it is a simple one and ideal as a tool for learning about distributed systems design, programming and testing.
The field of distributed systems is large, encompassing a myriad of academic work, algorithms, consistency models, data types, testing tools/techniques, formal verification tools and more. I will be covering just the theory, tools and techniques that were relevant for my little project.
DISCLAIMER: I am not an expert with years of experience specifically in distributed systems programming. My background has been in backend engineering, primarily in platform, operations and research teams. That said, I do have experience testing distributed systems and I am glad that I learned to test these systems before programming my first one.
What we'll be covering over the course of a few posts:
what the resource allocation library must do.
the design of the protocol that describes the what in more formal detail.
the formal verification of the protocol with TLA+.
a high level view of the implementation, also known as the how. We'll not be looking at actual code, but see how we translate a protocol (and TLA+ spec) into an implementation. The code is on GitHib though, so feel free to go and look it when it is ready. I used Apache ZooKeeper for coordination, though will be also be adding Etcd and Consul in the future.
the various types of testing of the implementation from integration tests that run from my IDE to chaos testing a deployed cluster.
I titled the post with “simple” in quotes because distributed systems always tend to end up complex in some way or other. With that let’s kick off the series.
What is the resource allocation library for and what will it do?
Think Kafka consumer groups. With a Kafka consumer group you have P partitions and C consumers and you want to balance consumption of the partitions over the consumers such that:
Allocation of partitions to consumers is balanced. With 7 partitions and 3 consumers, you’ll end up with 3, 2, 2.
No partition can be allocated to more than one consumer
No partition can remain unallocated
Also, when a new partition is added, or a consumer is added or removed or fails, then the partitions need to be rebalanced again.
Now replace the word partition with “any resource”. This library was born because I wanted consumer group functionality with RabbitMQ and its consistent hash exchange which can route to multiple queues by a hashing function, just like Kafka and its partitions. But this would work for any resource where you want this behaviour. In fact you don’t need to limit it even to resources but any “thing” that you want to balance a group of applications over.
The library is called Rebalanser. I replaced the “c” with an “s” because it’s obviously cooler that way. I did an initial implementation a while ago but didn’t take the time necessary to make it production ready. This series is about how I started it again from scratch, doing it properly this time. (Note that implementation is still in progress but close to finished at the time of writing).
This library will use in process events to notify the host application when it must start and stop accessing a set of resources. So the developer creates a couple of event handlers that will receive those events. Some graphical examples of a Rebalanser group in action.

Fig 1. The Rebalanser group starts off with two applications and five resources.
The two instances of the library agree between them on a valid allocation of the resources. Once agreed they let the application know when to stop and start access to those resources, via in process events.
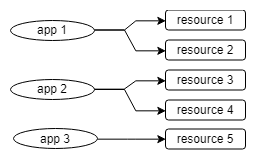
Fig 2. A new application is added to the group.
The Rebalanser group detect a new application in the group and come to agreement again about the new balanced resource allocations, including the new app 3.

Fig 3. Two new resources are added.
The Rebalanser group detect the addition of two more resources (added by the admin) and come to an agreement between them on a new balanced set of resource allocations.

Fig 4. App 2 fails or is shutdown.
The Rebalanser group detects that app 2 has either shutdown or failed. App 1 and 2 come to agreement on a new set of resource allocations.
We can also create a Single Active Consumer, or Active/Backup pattern:

Fig 5. A Rebalanser group of two applications and one resource.
In the above diagram we see that when there are more applications than resources in a group then the extra applications are in stand-by, ready to be allocated a resource in the case of new resources being added or an application shutting down or failing. In this case app 1 fails and app 2 takes over but at no point does the resource have both accessing it at the same time.
The library can, if we configure the group appropriately permit more than application to access a given resource at the same time, simply by creating “virtual” resources. Let’s say we have two resources and we want no more than three applications to access each one. Then we create 6 resources in the Rebalanser group and make those six resources point to only two real ones. As far as Rebalanser is concerned though, there are 6 resources.
System Invariants
Before I finish up and summarize the desired behaviours of the library, I want to introduce the word invariant and what invariants the Rebalanser library must ensure. Most/many should already know what it means but in case you don’t then an invariant is some rule or assertion of a system (or object) that must remain true throughout its lifetime. Rebalanser has the following invariants:
No resource should be accessed at the same by two different nodes (instances of the library).
All resources should be accessed in a reasonable amount of time after a rebalancing.
Invariant 1 needs to hold under all circumstances. Nodes failing, network partitions. We could be randomly adding/removing resources and nodes, randomly killing nodes, every 5-60 seconds for a week and no resource will ever have two nodes connected to it.
But there is one fundamental constraint on Rebalanser: it has no control or even have knowledge of the application’s access to the real resources. Rebalanser is allocating resources that the admin has registered in the group. Each resource is just a string. So Rebalanser could work perfectly, but if the programmer has not written their event handlers properly and the application does not successfully start or stop accessing the resources then we might end up with two resources been concurrently accessed or not accessed at all.
Also, invariant 2 is somewhat difficult to prove as we cannot really define “a reasonable amount of time”. So perhaps we should just use the word eventually. It basically means that a rebalancing cannot get stuck and leave resources not being accessed. Also, a rebalancing can be interrupted. Rebalanser puts no time limit on the Start and Stop event handling in each application. If it wants, an application can load a bunch of state from a database in either of its event handlers. This means that a rebalancing could theoretically take a long time, during which time resources may have changed, applications could have failed etc. Even short rebalancings can suffer the failure of a node midway which will cause a new rebalancing to get triggered. So a new rebalancing can cause the current one to abort. Obviously this could be very disruptive, so we want to provide a minimum time period between rebalancings.
So here are the two invariants again:
No resource should be accessed at the same time by two different nodes, given that each node correctly starts and stop access to the real resource(s) when instructed to.
A Rebalanser group will never become stuck or hung. Given the chance, all resources present at the beginning of a rebalancing will eventually be accessed.
I will be referring to these two invariants throughout the whole series.
What Rebalanser Should DO - Summary
So let’s summarize the list of things the library should do. We are not saying HOW it will do it.
Detect when a resource is added or removed.
Detect when nodes are added, or shutdown, failed or otherwise unreachable.
Come to an agreement on a balanced set of resource allocations such that all resources are allocated as evenly as possible.
Fire OnStart and OnStop events that inform the application what resources it should start and stop accessing.
Ensure that the invariants ALWAYS hold, even under failure scenarios. Nodes can fail, be network partitioned and the library needs to ensure the invariants.
Next we’ll look at the protocol - the behaviours which govern how each Rebalanser library acts in order to satisfy our list of requirements and invariants.
Note that the other posts are in the works. The work is pretty much all done, I just need to do the write up of each one. Expect the next posts over the course of the next couple of weeks.
Part 1 - The What (this post)
Part 6 - Testing the implementation (coming soon)
Banner image credit: ESO/C. Malin. Link to image