NOTE! This post covers the current Hudi design (April 2024) based on the v5 spec.
Apache Hudi is one of the leading three table formats (Apache Iceberg and Delta Lake being the other two). Whereas Apache Iceberg internals are relatively easy to understand, I found that Apache Hudi was more complex and hard to reason about. As a distributed systems engineer, I wanted to understand it and I was especially interested to understand its consistency model with regard to multiple concurrent writers. Ultimately, I wrote a TLA+ specification to help me nail down the design and understand its consistency model.
Hudi being more complex doesn’t mean Iceberg is better, only that it takes a little more work to internalize the design. One key reason for the complexity is that Hudi incorporates more features into the core spec. Where Iceberg is just a table format for now, Hudi is a fully blown managed table format with multiple query types. If you are well-versed in Delta Lake internals, you will also see that the Hudi design has a number of similarities to that of Delta Lake.
The scope of analysis
This analysis does not discuss performance at all, nor does it discuss how Hudi supports different use cases such as batch and streaming. It is solely focused on the consistency model of Hudi with special emphasis on multi-writer scenarios. It is also currently limited to Copy-On-Write (COW) tables. I’m starting with COW because it is a little simpler than Merge-On-Read and therefore a better place to start an analysis.
Part 1 - Building a logical model of Copy-On-Write and Merge-on-read tables.
Let's start with the basics
We’ll explore the fundamentals of the timeline, the metadata table, and file groups, and how a writer leverages them in tandem to execute read and write operations. This post aims to construct a logical mental model of the algorithm used to perform reads and writes.
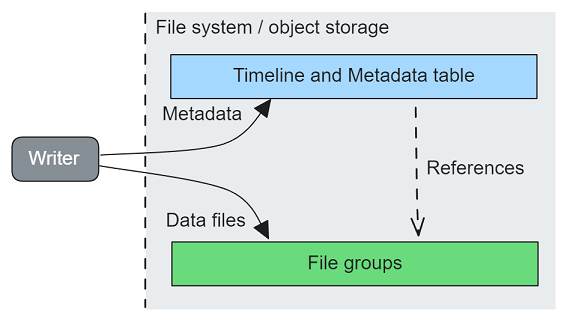
Fig 1. A writer writes metadata about data files to the timeline (a write-ahead-log)
The metadata is split between two components:
The timeline.
The metadata table.
The timeline is a log of metadata that describes the operations that have occurred, and the locations of the data files that were added or logically deleted in those operations.
The Hudi metadata table contains a list of all the committed data files that make up a Hudi table. Each table commit writes to the timeline and to the metadata table. This list of committed data files can be combined with the timeline, to return the set of files for any given table version, stored in the timeline.
The very basic idea behind how Hudi works is that:
Writers write data files (Parquet usually) and commit those files by writing the file locations to the timeline.
Different types of queries use the timeline and metadata table differently:
Snapshot queries execute on the lastest version of the table. They obtain the data files needed for scanning from the metadata table.
Time-travel queries pick a timestamp from the timeline and use the metadata table to obtain the data files that correspond to that moment in time.
Incremental queries walk the timeline and obtain the data files of each commit from the timeline.
ACID transactional guarantees
Hudi says it supports ACID transactions and this analysis will put that statement to the test.
Looking at the basics of how the timeline and file groups work, it looks clear that atomicity is trivially achieved, in a similar fashion to that of Apache Iceberg. In Hudi, write operations can only add new files, they never update files or delete files. Despite writing to two places, a Hudi write operation is an atomic operation as the final write to the timeline is what makes any new files in the file groups visible. Because no existing files are mutated, and the final commit of a single file makes all the new files visible at once, we get this atomicity. If a writer failed midway, then the final write to the timeline would not occur and the uncommitted files would remain invisible, to be cleaned at a later time by table services. It is a similar approach to Apache Iceberg, in the sense that if the Iceberg writer fails before updating the tree root via the catalog, then the changes are not readable.
Durability also looks safe, if we assume everyone is using these table formats over cloud object storage. Or other similarly redundant highly available storage systems.
That leaves Consistency and Isolation as the remaining properties of ACID that I want to understand and verify. In single writer scenarios, which is the predominant usage pattern of Hudi, these two would also probably be trivially true. However, I want to understand consistency and isolation in concurrent multi-writer scenarios, which is what the rest of this analysis focuses on.
Primary Keys
In Apache Hudi, every record has a primary key and each key is mapped to a single partition and file group (more on that later). Hudi guarantees in most cases that a primary key row will be unique, however, as we’ll see later on, there are a couple of edge cases that can cause duplication. However, in general, it is helpful to remember that Hudi bakes primary keys into the design, which sets itself apart from Apache Iceberg and Delta Lake.
I will often refer to primary keys simply as keys in this analysis.
The timeline
All operations, including table maintenance jobs, go through the timeline. The timeline is not an append-only log but a directory of files with ordering rules based on the file names.
Each operation is encoded as a set of “instant” objects, with a file name formatted as: [Action timestamp In Milliseconds].[Action type].[Action state]. This file name constitutes the id of the instant. Note that the docs talk about timestamps using millisecond resolution but you could also use logical timestamps.
There are many action types, with a few related to table maintenance jobs. In this post, we’ll only look at the Commit action type, which is used to perform insert, update and delete operations on COW tables.
There are three action states:
Requested
Inflight
Completed
A successful Commit operation will have each action state written as a separate instant file to the timeline, in the above order. The “completed” instant of a Commit operation contains the file locations of the files created by the commit. Readers and writers can scan the timeline for completed commit instants to learn of committed files and their locations.
The timeline is just a set of files on the filesystem or in object storage, so the ordering of the timeline is based on file names, using the following precedence:
Action timestamp.
Action state.
Two successful write operations with timestamps 100 and 101 would create a timeline ordered as follows (regardless of insertion order):
100.commit.requested
100.commit.inflight
100.commit
101.commit.requested
101.commit.inflight
101.commit
Note that the “completed” action state is omitted from the instant file name.
The Hudi spec states that the action timestamp should be monotonically increasing. What this means in the real world was not clear to me at first. It could be interpreted as:
Option 1) Timestamp issuance. When a writer obtains a timestamp, it obtains a (globally) monotonically increasing timestamp.
Option 2) Timeline insertion. The insertion order into the timeline is based on monotonically increasing timestamps. In other words, the insertion order matches the timestamps obtained by writers. An instant with ts=1 would not be added to the timeline after the instant with ts=2, for example.
We shall also assume that it means that two writers would never use the same timestamp - a timestamp collision. This poses the question of what happens if more than 1000 writes a second are attempted (and we run out of available milliseconds in a second). This is not a workload that is currently suited to any of these table formats. If it ever were then logical timestamps would be a good alternative. The timestamp is basically an int64 and the algorithm itself doesn’t care the meaning behind the number. Only if reads based on wall clock time were desired would logical timestamps be problematic.
Option 1 can be achieved in multiple ways, such as with an OLTP database, DynamoDB or even an Apache ZooKeeper counter. But even if the obtained timestamps are monotonic, two concurrent writers may not necessarily write to the timeline in the same order.
Example:
W1 obtains ts=100 from ZK.
W2 obtains ts=101 from ZK.
W2 puts 101.commit.requested.
W1 puts 100.commit.requested.
W2 puts 101.commit.inflight.
W2 puts 101.commit.
W1 puts 100.commit.inflight.
W1 puts 100.commit.
Remember that the timeline is just a directory on a filesystem or object store (as a prefix) and cannot itself impose an order. Ordering is done via sorting in the client on reading the timeline files.
Fig 2. Timeline ordering is by timestamp and not insertion order.
The only way of achieving strict insertion ordering (option 2) would be via a type of pessimistic locking that would wrap the entire set of operations, including obtaining the timestamp. Hudi does not do this, therefore, we must conclude that monotonic timestamps apply to issuance time, not write time.
We’ll explore the implications of monotonic vs non-monotonic timestamps, as well as locking options later on. While I will discuss the subject of non-monotonic timestamps and timestamp collisions in this analysis, it’s important to remember that non-monotonic timestamps violate the Hudi v5 spec (for good reason as we’ll see).
For now, we still have more of the basic mechanics to cover. Next, how the data files are written.
File groups
Data files are organized into partitions and file groups where any given primary key maps onto one file group. I mostly ignore partitions in this post to keep things as simple as I can as the scope is the consistency model.
The nature of a file group depends on whether the table is configured with copy-on-write (COW) or merge-on-read (MOR).
We’ll use a set of three commits to the FavoriteFruit table with columns:
Name (PK)
Fruit
The figure below shows expected results of a table scan at different timestamps which we’ll use to understand the difference between COW and MOR file groups.
Fig 3. Three commits that insert, update and delete rows, alongwith the expected table scan results at different timestamps.
COW tables
In COW tables, all data files are known as base files. Any inserts, updates or deletes of keys of a given file group will cause a new version of the Parquet base file to be written. The writer must read the current Parquet base file, merge the new/updated/deleted rows, then write it back as a new base file.
Hudi also has the concept of the file slice, which in a COW table consists of a single base file. The need for file slices will become evident with MOR tables that we will look at after COW tables.
The base file name contains the timestamp of the commit that produced it. To find the right file slice to merge, the writer scans the timeline for the timestamp of the most recent completed instant. This timestamp is the merge commit timestamp and it is used to find a merge target base file that will be merged to form a new base file (and file slice). The merge target is the committed base file with the highest timestamp <= merge commit timestamp. A committed base file is one that is referenced in a completed instant in the timeline. Once the in-memory merge is done, the writer writes the new base file to storage.
The file group is identified by its file id, and a base file is identified by:
its file group (file id)
the write token (a counter that is incremented on each attempt to write the file)
the action timestamp that created it.
The filename of a base file is in the format: [file_id]_[write_token]_[timestamp].[file_extension]
I will ignore file write retries for now so I will often refer to a file slice in the format [file_id=N, ts=M].
Fig 4. Each commit results in a new base file.
MOR tables
MOR tables are made up of base files and log files. Each write creates log files which are either data or delete files. A file slice consists of a base file and a number of log files that are layered on top of it. A read at a given timestamp must identify the file slice that matches the timestamp, read the base file and the log files on top that are equal to or below the read timestamp.
Fig 5. Depicts the same three commits, plus a compaction. The three commits result in one base file and two log files on top. A subsequent compaction rewrites the file slice as a new base file.
It is the job of compactions to prevent too many log files building up, which increase the cost of reads.
Hudi commit operations never overwrite or delete data files in file groups, they can only add new ones. It is the job of the table services such as cleaning to physically delete files.
Timeline and file groups together
Readers and writers use the timeline to understand which file slices, at a given timestamp, are relevant.
Fig 6. Timeline completed instants point to immutable data files.
File slices written without a corresponding completed instant are not readable and cannot be used as the merge target of a COW operation.
Fig 7. The operation at ts=150 fails before writing a completed instant, therefore its file slice remains unreadable.
A simple logical model of the write path
“All models are wrong, some are useful.” George Box.
We’ll try to understand Hudi consistency and isolation by building a simplified model of the Hudi design. The writer logic is broken down into a number of steps. Those steps vary depending on which concurrency control mechanism is chosen. Concurrency control isn’t always needed, such as with a single writer setup that embeds table services jobs into the writer. However, in multi-writer scenarios, concurrency control is required.
The model is made up of:
Timestamp provider
Lock provider
One or more writers, where each has some logic:
A write operation is broken down into a number of steps.
Concurrency control (none, optimistic, pessimistic)
Storage
Timeline directory
File groups
Indexes
Storage supports PutIfAbsent or not. When storage supports PutIfAbsent, the writer will abort on any timeline or file group write where the filename already exists. Else it will silently overwrite existing files that have the same filename/path.
Operations are based on KV pairs, with upserts or deletes. Each key corresponds to a primary key and the value to the associated non-PK column values.
Write path with Optimistic Concurrency Control (OCC)
I have modeled the logical write path with OCC as 9 steps. This might seem a lot, but it’s worth remembering that Hudi bakes primary keys into the design, which adds some additional work. Primary key support was a goal of the project.

Fig 8. The write path of the simplified model, with optimistic concurrency control.
Steps:
Obtain timestamp. A writer decides to perform an op on a primary key and obtains a timestamp.
Append Requested instant. The writer writes the requested instant to the timeline.
Key lookup. The writer performs lookups on the key to:
See if the key exists or not (for tagging an upsert as either an insert or update).
Get a file group, assigning one if it’s an insert. When assigning a file group to a new key, the writer chooses one from a fixed pool, non-deterministically (in the real world there are a number of file group mapping strategies and implementations).
Read merge target file slice. Read the merge target file slice into memory (if one exists)
Load the timeline into memory (first time it is loaded).
Scan the timeline for the merge commit timestamp. This is the action timestamp of the most recent completed instant.
Scan the timeline for completed instants that touch the target file id and that have a timestamp <= merge commit timestamp. If the set is non-empty, then the writer chooses the instant with the highest timestamp from that set, as the merge target file slice. If the set is empty, go to the next step.
Check that the timestamp of the merge target file slice is lower than the writer’s own action timestamp. It is possible to find a file slice to merge that has a higher timestamp than the writer’s own action timestamp (due to concurrent writers), if so the writer should abort now.
Reads the merge target file slice into memory.
Write file slices. Merge the op with the loaded file slice (if one existed) and write as a new file slice of the file group. If this is a new file group, then there was nothing to merge, only new data.
Acquire the table lock.
Update the indexes.
In the case this was an insert, the assigned file mapping for this key must be committed to the file mapping index.
Optimistic Concurrency Control check.
Load the timeline (second time it is loaded)
Scan the timeline for any completed instants that touch the target file group with an action timestamp > the merge target file slice timestamp (not the merge commit timestamp).
If such an instant exists, it means that another writer has written and committed a conflicting file slice. Therefore the check fails and the writer aborts. If no such instant exists, the check passes.
Write completed instant. Write the completed instant to the timeline with the location of the new file slice that was written.
Free the table lock.
Note the above assumes just a single merge target file slice as this model only includes single primary key operations right now. In case the concurrency control is not clear, I cover it in more detail in the Concurrency Control section further down.
Write path with Pessimistic locking
The difference with this approach is that the writer acquires per-file-group locks before any file slice is read, merged and then a new one written. Then no check is needed later, as is the case with OCC. These locks are held until the completed instant is written or the operation is aborted.
Fig 9. OCC check and table lock is replaced with per-file-group locks.
Pessimistic locking is not commonly used as there might be many hundreds, thousands or even millions of file groups. Large operations would need to acquire huge numbers of locks which is not ideal. So optimistic concurrency control is the preferred method.
A quick look at the TLA+ Next state formula
The TLA+ specification Next state formula reflects the write path described.
Fig 10. The next state formula of the TLA+ specification
The above tells the model checker that in each step, it should non-deterministically select one of the writers and non-deterministically execute one of the possible actions at that moment in time. For example, if a writer has just written the Requested instant, then the only possible next actions that could happen are KeyLookup or WriterFail.
Concurrency control
Concurrency control (CC) ensures that multiple operations do not tread on each other, causing consistency issues. Two operations that touch disjoint sets of file groups will not interfere with each other, so their CC checks will pass. It is only when two operations share one or more common file groups that the possibility of a conflict arises.
Fig 11. Disjoint file group commits have no conflicts.
This is a nice property of Hudi that I imagine helps in multi-writer scenarios where each write touches a small subset of the file groups. However, in cases where each writer is performing large batches, I imagine this benefit is somewhat reduced as each operation would likely touch a large number of file groups.
The v5 spec mentions two types of concurrency control:
Optimistic concurrency control
Pessimistic locking
Optimistic concurrency control (OCC)
Optimistic concurrency checking works as follows:
Two writers (W1 and W2) must merge some changes into file group 1 (w1 at ts=100 and w2 at ts=101). Each identifies an existing file slice of that file group to merge (the merge target). In this example, both identify file slice [file_id=1, ts=50] as the merge target.
W1 optimistically writes file slice [file_id=1, ts=100]
W2 optimistically writes file slice [file_id=1, ts=101]
Both these file slices are uncommitted and still unreadable as they have no corresponding completed instant in the time. Note also that they could have identified different merge targets if both had read the timeline at different times, causing each of their views of the timeline to be different.
W2 acquires the table lock first.
W2 loads the timeline again. It performs the CC check by scanning the timeline for a completed instant that touches file_id=1 with a timestamp > 50. It finds none so its CC check succeeds and it writes the completed instant. File slice [file_id=1, ts=101] is now committed and readable. W1 releases the table lock.
W1 acquires the table lock. W1 loads the timeline. It performs the CC check by scanning the timeline for a completed instant that touches file_id=1 with a timestamp > 50. It finds ts=101 and therefore the CC check fails and it aborts, and releases the table lock.
For example, in the below scenario, either w1 or w2 could now acquire the table lock and successfully complete the operation.
Fig 11. Either w1 or w2 could now acquire the table lock and successfully complete the operation.
However, once one writer has completed its operation, the second writer, on performing its OCC check, would see a committed file slice with a timestamp > 50, and so it would have to abort.
This is what we see in the diagram below. W2 has already finished. W1 will do its OCC check next, and it will scan the timeline for a completed instant that touches FG1 with a timestamp > 50. It will find 101 and therefore abort. W1 should now clean up the uncommitted file slice [file_id=1,ts=100], else a table services job will do that at a later time.
Fig 12. The operation at ts=100 cannot commit now as its OCC check would fail.
The result is that file slices can only be committed in timestamp order. With OCC, it is not possible to commit a file slice with a lower timestamp than an existing committed file slice.
Pessimistic locking
Another strategy is to acquire per file group locks before starting the read->merge->write file slice process. This guarantees that no other writer can make conflicting changes to file slices during this process. But as I mentioned earlier, it can involve too many locks so OCC is generally preferred.
Primary key conflict detection
In addition to file group conflicts, primary key conflicts can also be optionally controlled. A primary key conflict can occur when concurrent inserts by different writers result in the same key being assigned to different file groups. In the TLA+ specification, the writer chooses a file group non-deterministically when assigning a file group to a new key. This can result in duplicates appearing in reads, as discussed here. In this simple model, the primary key conflict check ensures that a key-to-file-group mapping does not already exist with a different file group before adding the mapping to the index.
A simple logical model of the read path
I have modeled the logical read path as 3 steps. The reader first identifies the relevant file slices from the timeline, then reads those files slices into memory and applies the query logic to those rows. In the real world, file slice pruning based on partitioning and file statistics such as column min/max statistics in the metadata files would be used to prune the number of file slices that actually must be read.
Note that this model does not include timeline archiving and file cleaning, it assumes the timeline is complete.
Fig 13. The read path of this simplified model.
Next steps
Before we look at the model checking results, I want to cover timestamp collisions. The v5 spec makes it clear that timestamps should be monotonic, and not doing so violates the spec. However, I wanted to understand the impact of collisions and also get an idea of the probabilities of such collisions happening in practice. This knowledge will be useful when assessing how compliant to the spec an implementation should be. This is the subject of part 2.
Series links: