
Image credit: G. Hüdepohl (atacamaphoto.com)/ESO
First the TLDR!
TLDR: Apache Kafka doesn’t need fsyncs to be safe because it includes recovery in its replication protocol. It is a real-world distributed system that uses asynchronous log writing + recovery with some additional extra safety built-in. Asynchronous log writing allows it to provide robust performance on a variety of hardware and with a wide variety of workloads.
Now that the TLDR is done, let’s dive into it.
The fact that by default Apache Kafka doesn’t flush writes to disk is sometimes used as ammunition against it. The argument is that if Kafka doesn’t flush data before acknowledging produce requests then surely the cluster can lose acknowledged data due to crashes and reboots. It sounds plausible and so people may believe it - but I’m here writing this today to explain why that isn’t the case.
What is an fsync / flush?
The term "fsync" and “flush” refers to an operating system call (known as a sys call) that ensures that data written to a file is physically stored on the storage drive. It is used to synchronize a file's in-memory state with its on-disk state.
Basically, if data is written but no fsync is performed and then the computer itself were to crash, be rebooted or lose power, those file changes would not be persisted.
Kafka does not flush synchronously - that means that, by default, it will not always flush before acknowledging a message. Before we explain why async flushes are ok for Apache Kafka, let’s look at why they’re unsafe for Raft.
Why Raft needs fsyncs
I am not picking on Raft - I love Raft! Just check out my GitHub repo on Raft, and blog post about Flexible Raft. Go check out RabbitMQ Quorum Queues which I was lucky enough to be a part of while at VMware. Just look at KRaft in Apache Kafka! Raft is awesome, and it needs fsyncs.
In a nutshell
The Raft protocol is essentially a group of servers where each server runs the same logic and is backed up by a log of operations persisted to disk. This protocol includes leader elections, failure detection, data replication, changing cluster membership and so on.
Fig 1. Raft is a state-machine replication (SMR) algorithm which consists of a cluster of state machines which sit on a replicated log.
A Raft cluster cannot tolerate losing any log entries that were previously written to disk. Raft depends on the log itself for the correctness of the protocol and so if the log on one node loses data it can compromise the correctness of the entire cluster.
If an entry is written to disk but then the server crashes and loses that entry, Raft can lose the copies of that data stored on other servers - that is, losing an entry on one server can cause all servers to lose that entry! Therefore each Raft server must fsync data written to disk.
The why (for those that want to understand more)
The main reason for the dependency on the integrity of the Raft log is that leader elections can cause servers to delete acknowledged data if any Raft server loses entries in its log.
Raft requires majority quorums to operate. For example, if we have three nodes, then there are three possible quorums that form a majority (of 2 nodes).
Fig 2. Three possible quorums of two nodes: {n1,n2}, {n2,n3} and {n1,n3}.
There are two types of quorum in Raft:
An election quorum: a group of nodes that all vote for the same node.
A replication quorum: a group of nodes that host a given message (and all prior messages).
A successful election requires the following things:
A majority of nodes to vote for the same node.
Each node must only vote for another if it has the same or more recent data. A node without the latest data won’t be elected.
The crux of the design is that Raft guarantees that the replication quorum of the most recent entries overlaps with all possible election quorums. That is to say, at least one node of any election quorum will have the latest data and only the node with the most recent data can win the election - so we guarantee that the new leader has all the data.
The overlapping of replication and election quorums is the cornerstone of Raft.
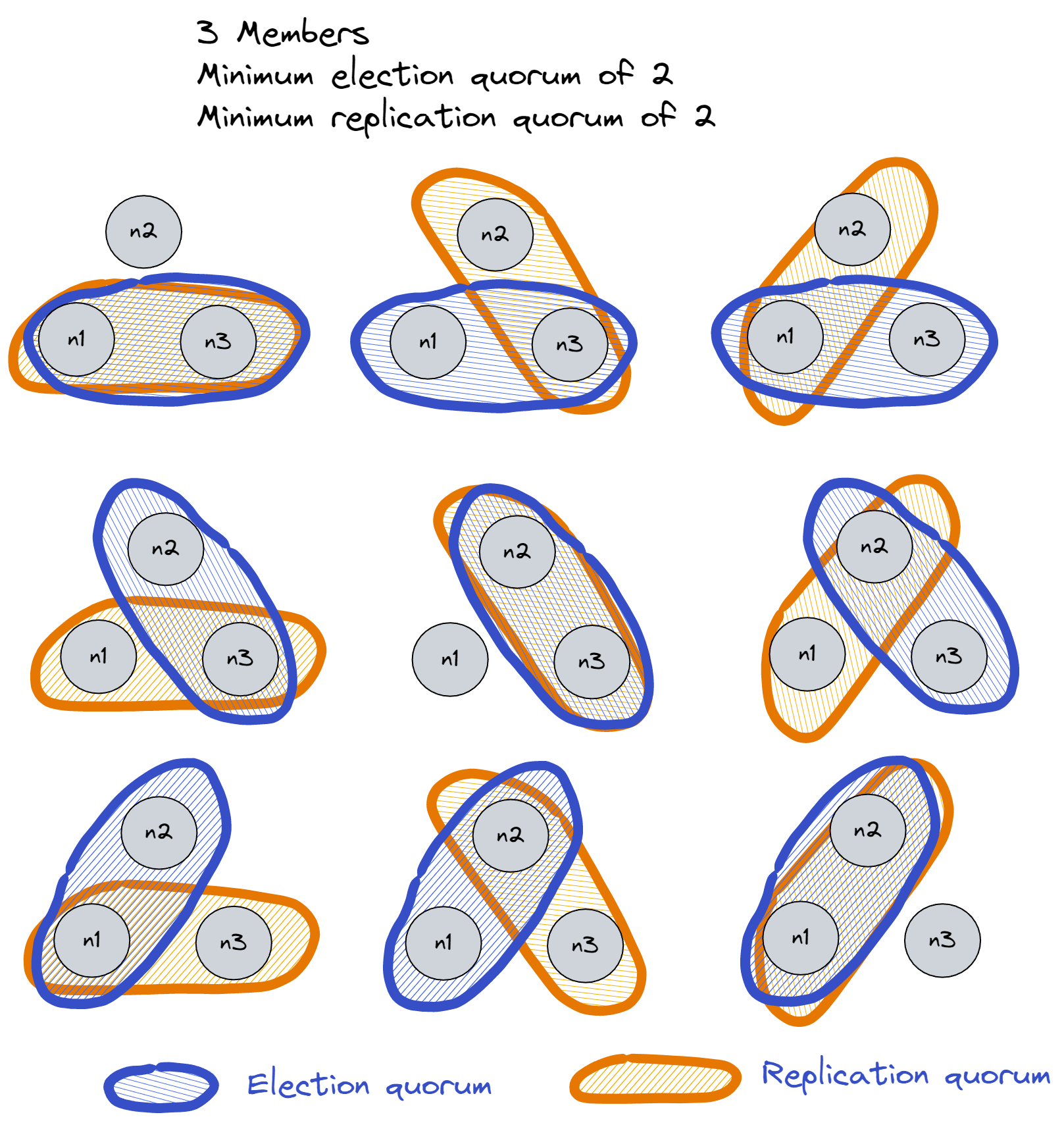
Fig 3. There exist no two replication and election quorums that do not overlap.
So what happens to Raft if nodes don’t fsync?
The answer is that the cornerstone of overlapping quorums is broken.
A simple example of Raft data loss without fsync
Let’s use a simple example of a Raft cluster with a handful of messages.
Messages m1, m2 and m3 have been added to the log, replicated to by a majority and acknowledged to the clients. Raft guarantees that these three won’t be lost as long as a majority of nodes are not lost.
Raft example step1: all is good.
But then the server of broker 1 fails/loses power, and it hadn’t performed an fsync causing m2 and m3 to be lost.
Raft example step2: broker 1 loses m2 and m3.
Broker 1 comes back with only m1. Broker 1 starts an election (ignoring pre vote here).

Raft example step3: Broker 1 is back with only m1.
Now b1 and b3 can form an election quorum which does not overlap with the replication quorum of m2 and m3 (which is only b2 now).
In the end, b1 and b3 both vote for b1, and so b1 becomes the leader. This causes b2 tol delete m2 and m3 from its log.
Raft example step 4: Oh no! An election and replication quorum that don’t overlap!
The Raft cluster just lost two acknowledged messages.
Raft example step 5: Broker 2 truncates its log to m1. The cluster just lost two acknowledged entries.
So vanilla Raft needs fsyncs to be safe and all implementations I know of do so. Of course you could modify Raft to not fsync but you’d need a recovery protocol and changes in when a node can be a candidate for leader. In fact, that is exactly what we’ll look at now, but with the Kafka replication protocol.
Why is Kafka safe despite not flushing every message?
In a nutshell
The answer is that Kafka’s data replication protocol was designed to be safe without fsyncs. Kafka replication does not depend on the integrity of a topic partition for leader elections, instead it depends on an external metadata store such as ZooKeeper or KRaft. A topic partition can lose some messages without compromising the correctness of the data replication protocol itself.
In order to cope with the loss of some messages on one broker, Kafka has in-built recovery or self-healing mechanism that automatically repairs the data. This recovery mechanism is what makes Kafka safe without fsyncs.
The why (for those that want to understand more)
Asynchronous log writing has been the subject of much research in the distributed systems community, with many real-world examples such as VSR Revisited (1, 2, 3) and Apache BookKeeper with the journal disabled.
There is one down-side to asynchronous log writing with these two systems - simultaneous crashes can cause data loss. Having run different distributed systems in production, in some cases at very large scale, I have seen cluster crashes occur, such as cascading OOMs taking out a cluster under high load, or a bug causing all nodes to crash at about the same time. Kafka is not subject to that issue because it doesn’t store unflushed data in its own memory, but in the page cache. If Kafka crashes, the data doesn’t go bye bye and for this reason Kafka is actually safer than BookKeeper without the journal - despite both using recovery protocols.
So how does the Kafka data replication protocol get away without fsyncs? It’s all about recovery.
Kafka replication and recovery
All distributed systems that write to storage asynchronously have a recovery mechanism built-in that allows an affected node to recover any data that was lost due to an abrupt termination of the node.
All these recovery mechanisms have the following rules in common:
The affected node must recover lost data from a peer.
The affected node cannot be a candidate for leadership until it has at least recovered the data it previously lost.
The recovery process with Kafka is very simple.
A failed broker restarts, having lost some number of messages that were not successfully stored to disk. Let’s say the log had 1000 messages, but lost the last ten meaning the last offset is now 990.
The broker has been removed from the ISR (the quorum which are leader candidates). The broker starts fetching at offset 991 from the existing topic partition leader, adding the messages to its own log. The first ten messages recover those lost earlier.
Once the broker is caught up, it is able to join the ISR as a fully functional broker that is a candidate for leadership.
The point is that until the affected broker catches up (and recovers any lost data), it cannot become a leader and therefore there can be no data loss. This concept of a node not being a leader candidate until it has at least recovered what it lost is the fundamental principle behind all three recovery protocols I am aware of.
An example of recovery
Kafka example step 1: All is good though the ISR is down to two to make this similar to the “Raft without fsync” example.
For whatever reason, let’s say the ISR only includes a majority, like our Raft example. This means that acknowledged messages might only exist on 2 brokers, as is the case with messages m1, m2 and m3.
Then the server of b1 crashes/loses power, causing m2 and m3 to be lost on broker 1. At this point broker 1 is removed from the ISR and stops being a candidate for leadership.
Kafka example 2: The server of broker 1 goes offline, taking the page cache with it and losing m2 and m3.
Broker 1 comes back online, without messages m2 and m3.
Kafka example step 3: Broker 1 comes back without the unflushed messages m2 and m3.
Broker 1 starts fetching messages from the leader, starting at offset of m1 + 1. Once broker 1 has caught up, it gets included in the ISR again. Any future leader elections can safely include broker 1.
Kafka example step 4: Broker 1 fetches from broker 2 until it is caught up and rejoins the ISR.
Only brokers in the ISR can become the leader and all brokers in the ISR have the complete log - there is no equivalent data loss scenario like with “Raft without fsync”.
The Last Replica Standing issue
There is however one edge case where Kafka, as of version 3.5 today, does not correctly handle recovery which can allow for data loss. I have written about this edge case and KIP-966 which addresses it.
Handling cluster-wide failures
Kafka may handle simultaneous broker crashes but simultaneous power failure is a problem. If all brokers lose power simultaneously then there is a risk of data loss. Every system makes trade-offs and this is one of Apache Kafka’s. However, luckily for us, there’s a simple solution.
High availability and high durability are only truly possible when clusters are spread over multiple data centers. In the cloud this means spreading clusters over multiple availability zones where each zone is actually a physically separated data center. This avoids disasters such as fires or power surges from destroying all copies of the data and allows a system to remain available.
Asynchronous log writing designs like Kafka are most durable when spread over multiple zones to avoid power outages from causing all brokers to simultaneously and abruptly stop which could lead to some unrecoverable data. This is a common argument against Apache Kafka however the truth is that organizations that care about durability should be using multi-zone deployments in any case.
In summary
Apache Kafka was designed up front to be safe without fsyncs by including recovery in its replication protocol. Kafka isn’t the only kid on the block that does this and it provides some real world performance benefits. I will be starting a Kafka performance series very soon where we will see how asynchronous log writing is Kafka’s secret weapon, one of the ways it is able to delivery huge throughput and low latencies safely on all kinds of hardware and all kinds of workloads.
One of the cool things about having worked in the RabbitMQ Core Team, been part of the Pulsar-as-a-service team at Splunk where I wrote code for Apache Pulsar and Apache BookKeeper, and now at Confluent helping move Apache Kafka (and our cloud) forwards is that I get to write about the cool design decisions that each system has made. I’ve written a lot about RabbitMQ, Pulsar and BookKeeper internals but not so much about Kafka yet. That is changing and I’m really happy to finally be able to spend some time on Kafka because quite frankly it rocks.
#kafkarocks