Introduction
Recently I wrote a blog post on my team blog about the differences between Raft and the Apache BookKeeper replication protocol. In it I covered one difference that surprises people which is that a ledger can have multiple blocks of entries that only ever reach Ack Quorum and not Write Quorum due to how ensemble changes work. A Raft log on the other hand has the property that the replication factor (RF) reached by any given entry matches the following:
Prefix RF >= Entry RF >= Suffix RFThat is to say, if a given entry has reached RF of 3, then the entire log prefix must also be at 3 or above (depending on the desired RF configured). But with BookKeeper that is not the case. For example, with WQ=3/AQ=2, a given entry that has reached RF of 3 may have entries before it that only reached RF of 2.
In this post we’ll explore what changes to the protocol would be necessary to guarantee write quorum replication on all entries of a ledger. First we’ll look at the existing behaviour and discuss the current meaning of Write Quorum (WQ) and Ack Quorum (AQ). Then we’ll discuss a change in the meaning of WQ and AQ and the protocol changes necessary to achieve it. Finally we’ll weigh the advantages and disadvantages.
If you haven’t read my post that covers write quorum and ack quorum in detail, then I recommend that you read that before reading this. This post is primarily concerned with ledgers that have AQ < WQ configured.
There are actually 3 reasons why an entry might remain at RF of AQ instead of WQ:
An ensemble change can leave the head of the now previous fragment at AQ.
The client closes the ledger, which can leave the head of the last fragment at AQ.
A recovery client completes recovery which can leave the head of the last fragment at AQ (having reached only AQ for some written back entries).
However, there exist protocol changes that would give us the following guarantees:
All entries in all but the last fragment of open ledgers will be at RF=WQ.
All entries of a closed ledger will be at RF=WQ.
This will give us that same shape as a Raft log and make BookKeeper behaviour more closely align with most users expectations.
Write quorum and ack quorum today
Write quorum is the best effort replication factor of any given entry. Ack quorum is the minimum guaranteed replication factor of a committed entry. When an entry reaches AQ it can be acknowledged but there are no guarantees it will reach write quorum.
However, ack quorum is usually interpreted to mean the number of bookies that must confirm an entry before the entry can be acknowledged. While this is true, it misses the fact that the entry may only remain at AQ.
Another thing to note about write quorum is that a ledger cannot make sustained progress without write quorum healthy and available bookies. Short-term progress can be made with only ack quorum bookies but only until the next ensemble change which will fail due to there not being enough available bookies. When a ledger handle cannot progress due to lack of bookies, it closes the ledger.
Case study
Fig 1. A series of ensemble changes leaves multiple entries at AQ.
This series of responses and ensemble changes leaves us with the entries as seen in the top example:
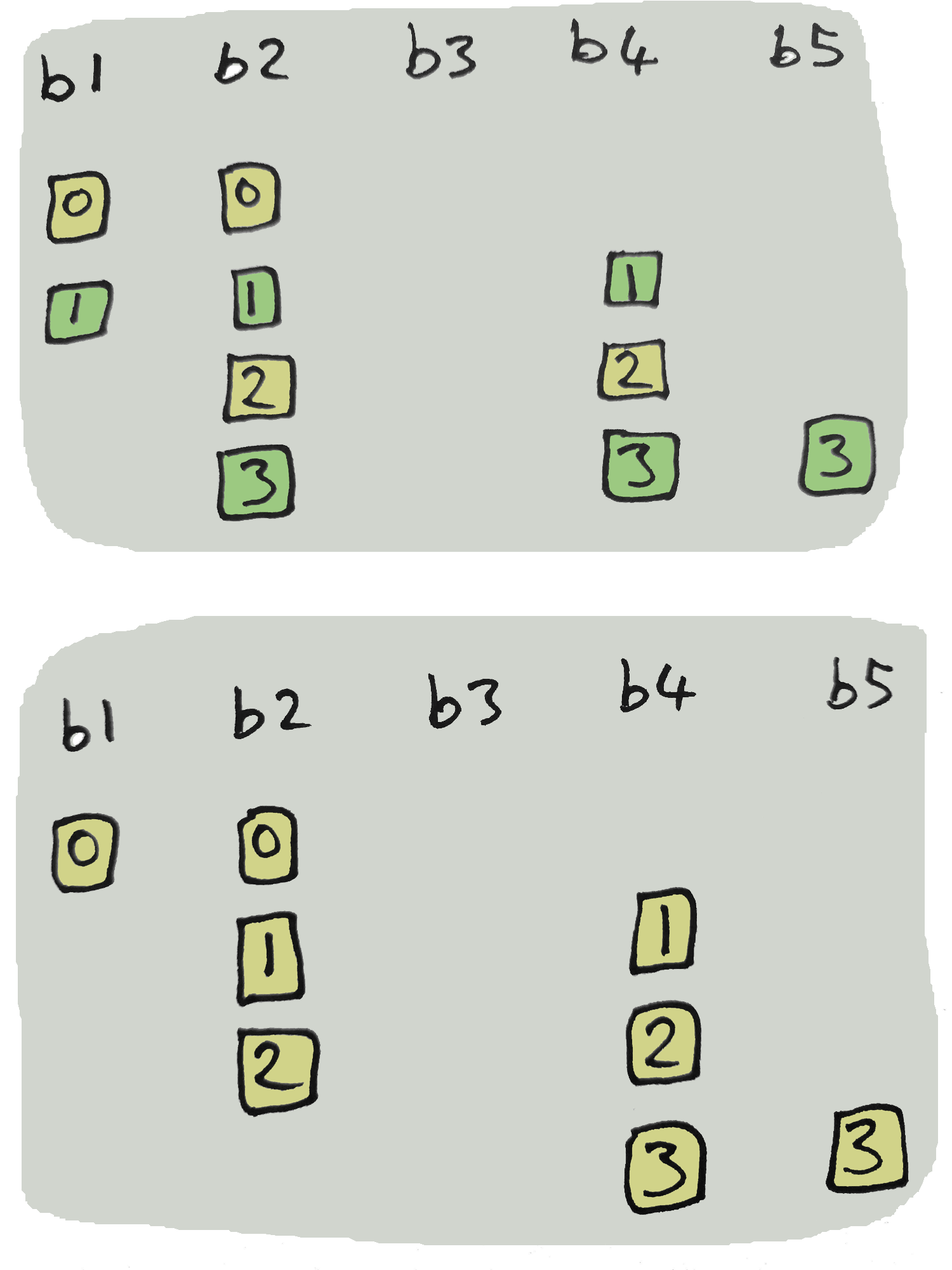
Fig 2. WQ=3, AQ=2. Top: entries 0 and 2 left at AQ after ensemble changes. Bottom: all entries left at AQ is also a legal state of a ledger with WQ=3, AQ=2.
The bottom example can be arrived at if b1 responded with an error for entry 1 and b2 had responded with an error for entry 3.
It is legal for an entire ledger to only reach AQ.
On guaranteeing write quorum
What if we changed the meaning of WQ and AQ to the following:
Write quorum is the guaranteed replication factor for all entries in a closed ledger. For open ledgers, write quorum is the guaranteed replication factor of all entries except the last fragment (aka the current ensemble).
Ack quorum is the minimum number of bookies required to acknowledge an entry write.
In this modified meaning our logs that we create by chaining ledgers together (like Pulsar topics) will have the Raft log shape where only the committed head can be at the minimum quorum, aka:
Prefix RF >= Entry RF >= Suffix RFThe protocol changes for guaranteed write quorum
First we’ll look at what doesn’t work and then cover the changes that will work.
What won’t work
The simple case is to retry failed writes but this can only be best effort. It is possible the failed write is due to a bookie being down and it could be down for a very long time, the client cannot keep entries in memory until it comes back.
Another option would be to move all entries that have not reached WQ into the next fragment. More specifically, all entries starting at the earliest that has not reached WQ. Unfortunately this can lose acknowledged data.
Fig 3. By moving acknowledged entries into the next ensemble, and changing the ensemble until its ensemble is completely disjoint from the bookies that host the committed entries, the committed entries become lost.
Committed entry 0 is unreadable. At this point the current ensemble (b4, b5, b6) is disjoint from the bookies that actually host the committed entry (b1, b2). If ledger recovery occurred now, it would truncate the ledger by closing it as empty. In fact, ledger truncation can happen after only a single bookie that hosts a committed entry gets removed from the ensemble. If the client closed the entry at entry 0, the entry would be unreadable. Either way, the entry is essentially lost.
The necessary changes that would work
The changes can be split into three categories:
Changes to make ensemble changes not leave AQ entries behind
Changes to make a client close a ledger without leaving AQ entries behind.
Changes to make a recovery client perform recovery and close a ledger without leaving AQ entries behind.
Note that none of the tweaks change the meaning of the LAC. The LAC is still sent with writes and reader clients still should not read past the LAC.
Tweak #1 - Ensemble changes
A ledger handle keeps all entries that have not yet been committed in an internal in-memory queue. A “pending add op” gets removed from the queue as soon a confirm is received from a bookie such that the following criteria is met:
The number of confirmations for that entry has reached AQ.
All prior entries have also reached AQ.
The first change matches the broken example above - we modify the criteria from AQ to WQ for removing add ops from the queue. We now want to bring all entries forward that have not reached WQ - specifically the contiguous block of entries starting at the lowest entry not to have reached WQ. When an ensemble change occurs all these get brought into the next fragment - including committed entries. But we don’t stop there, we also introduce bookie pinning to avoid the problem of losing committed entries.
When an ensemble change occurs, we pin bookies that are in the ack set of a committed entry that has not reached WQ. Pinned bookies are not eligible for being swapped out during an ensemble change.
The problem with the ensemble changes in the broken example are that bookies that host committed entries can be replaced in ensemble changes. If we prevent that, then ensemble changes don’t leave committed entries at AQ and can’t make committed entries unreadable.
Let’s take a happy case similar to fig 1.
Fig 4. A series of ensemble changes where entries starting at the first entry below AQ are moved into the next fragment.
The above leaves entries 0 and 2 at WQ instead of AQ like in fig 1. However, if b5 had responded with an error for entries 2 and 3, followed by the client closing the ledger then the head of the last fragment would have remained at AQ. To fix that we need other changes (see tweak 2).
Let’s look at a more unhappy path like in fig 3. Bookie pinning prevents data loss.
Fig 5. Ensemble changes that would have replaced bookies that hosted committed entries below WQ are postponed until they no longer host committed but not fully replicated entries.
In the above example, only e0 got committed, the rest did not reach AQ and e0 was set as the last entry id of the ledger on closing it. No data loss.
We can now safely move committed entries into new fragments without the risk of those entries becoming unreadable and lost.
Tweak #2 - Closing ledgers
This change relies on the previous change - specifically that any given pending add op is only removed if it and all prior entries have reached WQ.
A client can close a ledger at any time. This can leave the head of the last fragment at AQ. The change here is to only complete a ledger close operation once there are no remaining pending add ops (and hence all entries are at WQ). If we stop accepting new adds and wait until there are no pending add ops, we know that all entries are fully replicated.
Tweak #3 - Recovering ledgers
This also depends on tweak #1 and tweak #2. Recovery completes by closing the ledger, but tweak #2 states that we must have no pending add ops before we can close.
The additional change is that recovery can no longer start at entry LAC+1 because the LAC marks the head of the committed entries, but these entries might not have reached WQ. So recovery needs to either:
begin recovery reads at the start of the last fragment. This is quite inefficient though as there could be a large number of entries to read and write back.
or use a new tracking offset similar to LAC, but one that marks the head of the contiguous block of WQ replicated entries. Let’s called it provisionally Last Add Fully Replicated (LAFR).
If we go with the LAFR approach then we replace the fencing LAC reads at the beginning of ledger recovery with fencing LAFR reads. Also we need to include the LAFR as part of the regular write process. The LAFR is an optimization, it is not required for correctness like the LAC is. So we don’t need to include it in every write, just periodically.
Changing the meaning of Close
Currently if a ledger handle cannot make progress due to not enough bookies being available it closes the ledger, which is just a metadata operation.
If we want strict WQ for all entries then we need to make sure that close operations are now also replication dependant. This means that if a ledger handle cannot make progress, closing the ledger is now no longer an option. We either keep trying, or leave the ledger open for a later ledger recovery operation to attempt to close.
Currently, not having enough bookies means you can successfully close a ledger and then get blocked on creating the next until enough bookies become available.
With this change you are blocked from closing a ledger now, but can do so later once enough bookies become available, and then can create the next ledger and make progress.
Of course we could choose to make ledger closes best effort which could leave the last entries of a closed ledger only reach AQ. Given that a Pulsar topic is a log of ledgers, we’d essential have the same problem - AQ entries in the middle of the topic, though it would be less pronounced.
Auto Recovery and Data Integrity Checking Alternatives
Auto recovery is an optional process that can be run to fix under replicated fragments in an out-of-protocol asynchronous manner. Do not confuse it with ledger recovery which is a synchronous part of the replication protocol. It can detect the loss of a bookie and immediately replicate its data to another bookie. However, the issue of entries only reaching AQ cannot be detected that way, only a periodic full scan of the cluster can detect that. This can be a very expensive operation if you have a large cluster and lots of data. The default scan period is once per week.
The upcoming data integrity checking feature that will allow bookies to run without the journal will make fixing these under-replicated entries more practical. The data integrity check on a bookie is able to scan its index, self-detect any missing entries that an ensemble change or ledger close caused and source those entries from peer bookies. This operation is far cheaper and could possibly run hourly.
This makes data integrity checking a good asynchronous alternative.
Advantages and Disadvantages
Status Quo
Closing remains simple. We can fix the under-replicated entries asynchronously using the upcoming data integrity checking or periodic full scans using the auto-recovery process.
If users don’t want AQ blocks of entries in ledgers then use WQ=AQ but pay the price of latency spikes of any slow ensemble change operations.
“Guaranteed Write Quorum” Advantages
We get extra safety as part of the synchronous replication protocol when AQ < WQ. We also get behaviour that is more inline with users expectations - that there are no blocks of AQ entries in the middle of ledgers.
We get within a hair breadth of the safety of having WQ=AQ, but without the latency spikes associated with ensemble change metadata operations. If a write fails, we continue to acknowledge entries that have only reached AQ making ensemble changes non-blocking.
“Guaranteed Write Quorum” Disadvantages
Closing a ledger is no longer just a metadata operation. It depends on replication as well. Closing a ledger may not be possible in some scenarios, requiring ledger recovery to perform a close later on.
Memory usage will increase to the levels when WQ=AQ as pending add ops may be in the queue for longer. If low memory usage is very important, then this change may not suit you.
Formal Verification
These changes have been formally verified in TLA+ and are safe. You can find the TLA+ specification for this modified BookKeeper protocol in my BookKeeper TLA+ GitHub repo.
For those who know TLA+, the specification is a more precise description of what I have described in this post. If you haven’t experience of TLA+ then you can simply read the comments which are detailed and do a decent job of explaining things.
Final Thoughts
I am curious to know the opinions of the community and will bringing this up in the dev mailing list to see if people think it is worth creating a BP for it. The ledger close restrictions may be too tough to swallow, especially as it would require changes to the code that manages ledgers (like the Managed Ledger in Pulsar). There are also decent asynchronous alternatives.
These changes may in the end be better suited to go with the protocol changes I will describe in the next post - Unbounded Ledgers.
With unbounded ledgers we do not have to form logs by chaining bounded ledgers together, we could for example, have a Pulsar topic that is made of a single unbounded ledger. With this type of ledger, close operations are either never performed or performed once at most in the lifetime of a ledger. The protocol changes to achieve this are coming soon (next post).