
CockroachDB is a distributed SQL database that aims to be Postgres-compatible. Over the years, the Postgres wire protocol has become a standard of sorts with many database products implementing its wire protocol (much like the Apache Kafka protocol has become a de facto standard in the streaming space).
While it may be Postgres-compatible, there is almost nothing about the serverless CockroachDB architecture that is shared with Neon (serverless Postgres covered in the previous chapter). What they do share, like all the serverless multi-tenant systems in this series, is the separation of storage and compute; the rest is completely different.
The motivation behind investing in offering a serverless MT version of CockroachDB was:
Be able to offer a free tier to users who want to be able to kick the tires.
Provide a simpler way to buy managed CockroachDB (no upfront capacity analysis, just pay-as-you-go pricing).
Be able to cater to the market of users who actually just need a lot of small databases, rather than a couple of really large ones. CockroachDB is great at large databases and it turned out that this scalability was a great base for multi-tenancy.
Serverless CockroachDB may be serverless in the sense that you won’t be choosing between EC2 instance types, but it is still “clusterful” with virtual clusters. Many virtual clusters can be serviced by a single, much larger physical cluster. This is the same high-level approach Kora took. What both share is that the originally single-tenant systems were already horizontally scalable and capable of massive loads. This made them a good foundation for the large physical clusters over which the smaller virtual clusters could be run.
As the CockroachDB team explains, “This means that a tiny database with a few kilobytes of storage and a handful of requests costs us almost nothing to run, because it’s running on just a small slice of the physical hardware”. The economics of virtual clusters, especially for more numerous smaller databases, is clear - hence CockroachDB offering them for free.
Note that this is a long one!, so I’ve split it into three parts. It is a large and complex system that is worth taking some time to pick apart.
Warning, batteries not included
This analysis focuses on approaches to multi-tenancy, how it implements tenant isolation through various strategies. It does not include much of what makes CockroachDB what it is:
How it guarantees consistency, including the role of hybrid logical clocks (HLC) and uncertainty intervals.
How it does ACID guarantees and concurrency control.
It’s query optimizer
It’s multi-region data placement topologies.
etc…
These are all fascinating subjects too, so for the hardcore nerds, if you want to learn more about these aspects of CockroachDB I recommend two places:
The paper: CockroachDB: The Resilient Geo-Distributed SQL Database.
The source code: It’s open source and written in Go.
Architecture overview
CockroachDB (CRDB) is an impressive technology and it already had a lot of the ingredients needed for multi-tenancy and a serverless interface before the work to create a multi-tenant variant started. It is a fully distributed database capable of massive scale which it achieves through sharding, horizontal scaling, and a sophisticated admission control process that implements fair query scheduling and quota enforcement to prevent overload. What was needed to support a serverless MT offering was, you guessed it, to separate the compute-heavy parts from the storage-heavy parts.
Single-tenant CRDB
A CockroachDB cluster is formed by a group of nodes where each node comprises multiple layers dedicated to specific activities such as the SQL processing, replication and storage. CockroachDB divides data into ranges, where each range is a contiguous subset of the keyspace of the table or index. Ranges are replicated and distributed across nodes in the cluster.
Clients can connect to any node, and that node will either do all the SQL processing locally, sending out the KV operations to the nodes where the data is stored, or it will also federate the SQL query processing across multiple nodes, pushing down filters, joins and aggregations where possible. The node where a query lands is known as a gateway node. Any given row will be hosted in a single range which is replicated across three nodes. Only the range leader, called the leaseholder, can serve writes and consistent reads.
Fig 1. A single row insert query arrives at a gateway node, which sends a corresponding KV write operation to the relevant range leaseholder who in turn replicates it to its followers.
The CockroachDB node is composed of various layers which is each responsible for a slice of the work of servicing a read or write request:
SQL layer: Translates SQL queries into a set of KV operations. Generally speaking, the SQL layer lacks awareness of the partitioning or distribution of data as the underlying layers provide a monolithic abstraction of a KV store.
Transactional layer: Responsible for maintaining the atomicity of changes to multiple KV entries and to a large extent, the isolation guarantees.
Distribution layer: This layer presents the monolithic key space and under-the-hood routes KV operations to the correct ranges. This includes pushing down operations such as filters and joins where it can.
Replication layer: Replication of key ranges using the Raft algorithm. It is a leader-based layer where all writes and consistent reads must go through the leader, also known as the leaseholder. CRDB has leaseholders and also Raft leaders which are normally co-located.
Storage: The storage engine on each CRDB node is the Pebble KV store based on RocksDB.
Clients can connect to any node, so internal KV operations get routed to other CRDB nodes based on which nodes are the leaders of the range of a given KV operation.
Fig 2. The path of a write to a given key range. The distribution layer routes the operation to the second node, which acts as the range leaseholder. The leaseholder directs the write to the normally co-located Raft leader, which in turn replicates the operation to its followers.
Reads also get routed and federated across the nodes that cover the ranges touched by the SQL select operation.
Fig 3. A read operation is distributed across nodes that host the relevant range leaseholders.
The node where a SQL transaction is received is known as the gateway node and serves as the transaction coordinator for the query. The gateway node actively engages with the SQL client and oversees the transaction, ultimately either committing it or aborting. SQL query execution takes place in either of two modes: gateway-only mode, where the node planning the query handles all SQL processing, or distributed mode, involving participation from other nodes in the cluster for SQL processing.
Sharding (ranges)
The sharding mechanism consists of splitting up tables and indexes into a set of ranges where each range covers a contiguous block of keyspace. Each range is independently replicated and stored across multiple CRDB nodes using the Raft replication protocol.
CRDB employs range-level leases, with a designated replica in the Raft group serving as the leaseholder, typically the Raft group leader. This leaseholder exclusively handles authoritative, up-to-date reads and proposes writes to the Raft group leader. By channeling all writes through the leaseholder, reads can achieve consistency without incurring the networking round trips mandated by Raft. Lease acquisition itself is protected by Raft, with acquisitions being Raft commands that get committed in a system Raft group.
As ranges grow larger than the configured max size, they get split into two ranges; tables start as a single range and splitting occurs as the table grows. Likewise, adjacent ranges that have shrunk below this threshold get merged.
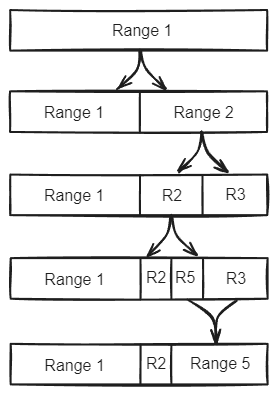
Fig 4. Ranges split and merge according to data size and load.
The Pebble KV store
Any given CRDB node may host multiple Raft groups but all ultimately write to a local shared Pebble KV store. All data is written to Pebble, even the Raft logs.
Fig 5. Each range replica writes table data and Raft data to a local Pebble instance.
Admission control (AC)
In single-tenant CRDB, the admission control sub-system is responsible for preventing the overload of individual nodes - in other words, it is a node-level protection mechanism and not distributed.
AC works by submitting work through work queues and sorting tasks into different priorities. Some tasks, such as important housekeeping or node health checks have higher priority and are preferentially executed over lower priority tasks.
The objective of admission control is to protect nodes from overload whether from aggregate load exceeding the cluster’s capacity or a skewed distribution focusing load on a small subset of nodes. To ensure stability, the extra query load on a node should not interfere with important tasks such as heartbeats which could result in disruptive actions such as unnecessary leader elections. CRDB has a data rebalancing mechanism that kicks in to dissipate hotspots and so admission control acts in the short-term as a protection mechanism until the rebalancing reduces the demands on that particular node.
I’ll cover admission control in much greater detail in the multi-tenancy section in part 2.
Cloud object storage
CRDB chose a different storage cost trade-off to Neon by not offloading data to cloud storage. This decision makes the storage layer more expensive but also avoids the latency trade-offs that cloud object storage introduces. The architecture of CRDB makes cloud storage a harder nut to track due to the limited caching options it has compared to Neon, which has better caching opportunities in its architecture. However, caches themselves can introduce hard problems (such as metastable failures) and are not a silver bullet. CRDB prioritizes more consistent latencies over pure efficiency or storage cost.
Fig 6. Choices for integrating (or not) cheap, durable cloud object storage. CRDB chose to store all data on storage nodes, avoiding the latency penalty.
CockroachDB could switch to the “durable write-cache in front of cloud storage” model, using read caching and prefetching (in the storage layer) to reduce latency for reads; but this design would be fraught with tail-latency dangers.
Multi-tenant CRDB
To build a serverless CRDB, some changes were needed as well as some new components.
Separating the monolith into compute and storage
For the serverless CRDB SKU, the Cockroach team decided to split the CRDB node into separate storage and compute nodes.
A shared storage layer was identified as an important design principle as it allowed a serverless CRDB “the ability to efficiently pack together the data of many tiny tenants”. The SQL layers would be deployed as more isolated per-tenant components due to the high variability of work performed by SQL queries. SQL has the double-edged sword of being extremely powerful and flexible, as well as causing wildly different amounts of work to be performed from one query to another. To provide good tenant isolation, it was clear that the SQL layer needed to be treated differently.
Thus the layers were grouped into compute and storage nodes.
Fig 7. Separating the CRDB node into compute and storage.
Virtual clusters over physical clusters
Serverless CRDB is decomposed into three principal layers:
Proxy
SQL compute
Shared storage
Virtual clusters operate over the top of this large disaggregated physical cluster.
Connections are load-balanced over a set of proxies, which in turn routes them to per-tenant stateless SQL pods. The auto-scaler component adds and removes SQL pods for a tenant as per-tenant load changes. The auto-scaler can even scale down SQL pods to zero. The proxy layer triggers a new SQL pod to be assigned to the tenant when a query comes in for a scaled-to-zero tenant. The query parsing and query distribution components live in the SQL pods. The storage layer is deployed as a set of shared storage pods that use logical isolation of tenant data.
Logical tenant isolation
Serverless CRDB takes a similar tenant id prefixing approach to Kora regarding how the data of each tenant is isolated. In the case of CRDB, this is the prefixing of keys which results in no ranges ever co-locating data of different tenants. Each tenant receives an isolated, protected portion of the KV keyspace. The SQL layer authenticates all requests and uses the authenticated tenant id to generate keys with the following pattern: /<tenant-id>/<table-id>/<index-id>/<key>. This means that key-value pairs generated by different tenants are isolated in their own ranges.
Proxy layer
The proxy layer plays a critical role in the multi-tenant architecture:
Performs load balancing over the SQL pods of a given tenant using a least connections algorithm.
Allows multiple tenants to share the same IP address and routes to per-tenant pods by identifying the tenant id from the SNI header.
Provides the ability to transparently move SQL connections from one SQL pod to another, which means that SQL pod load can be shifted if hot spots develop.
Trigger a new SQL pod to be provided when a connection is established for a tenant that is scaled to zero.
Next up in part 2
In the second part of this chapter on CockroachDB serverless, we’ll start digging into the various strategies for scaling and tenant isolation.
Chapter 4 parts: